Andes D1088 在汽车ADAS之应用
沈智明,资深经理,晶心科技股份有限公司
先进驾驶辅助系统(Advanced Driver Assistance Systems;ADAS)为现今 IT 产业发展之重要方向,是将来可以达到无人驾驶智慧车辆的技术进阶过程。ADAS 的主要功能并不是控制汽车,而是为驾驶人提供车内的工作情况与车外环境变化等相关信息进行分析,提供预先警告可能的危险状况,让驾驶人提早采取因应措施,避免交通意外发生。晶心科技的产品 D1088 具数字信号处理器(digital signal processor,DSP)指令,除了一般 CPU 指令外还多了 SIMD instructions 来加速ADAS 系统的演算,增加 ADAS 产品之性能,也因此获得客户的认同使用晶心科技 D1088 开发 ADAS 产品。使用 D1088 开发的 ADAS 产品包括盲点侦测(Blind-Spot Detection, BSD),前车碰撞警示(Forward-Collision Warning, FCW),车道偏移警示(Lane-Departure Warning, LDW),移动物侦测(Motion-Object Detection, MOD),倒车碰撞警示(Rear-Collision Warning, RCW),行人碰撞警示(Pedestrian-Collision Warning, PCW)及行车纪录器。
车 用 电 子 须 通 过 AEC-Q100(Automotive Electronics Council – Failure Mechanism Based Stress Test Qualification For Integrated Circuits)的认证,要求有别于一般消费性电子产品,本文之目的除了告诉我们的客户(IC设计业者)D1088的优势,也与我们的客户一起探讨车用电子与消费性电子产品间差异。希望在车用电子领域,晶心科技与我们的客户携手同行从今日开发ADAS芯片到未来的无人车自动驾驶。
1. D1088 应用于 ADAS 的优势
生活环境中都是模拟讯号,声音是模拟讯号,影像是模拟讯号,汽车碰撞的压力值还是模拟讯号,汽车在行进中,感知器将量测数值传送进 ADAS 控制器,经过 ADC 转换后得到数字讯号﹐车内外环境中充满了干扰与噪声,滤波器可以滤掉噪声与干扰,大大提升讯号正确性与可靠度,还原事物的原貌。文中以数字滤波器 FIR (Finite Impulse Response)为例,比较使用一般 CPU 指令与D1088 提供的 DSP 指令在实践 FIR 时的差异,说明 D1088 的优势与特性。
1.1 使用Fir_q15 函数验证
以 ADAS 中车道偏移警示系统会用到的 FIR 数字滤波器,使用 Fir_q15[1]
函数 C 语言实作如下所示:
void nds32_fir_q15(const nds32_fir_q15_t *instance,q15_t *src, q15_t *dst, uint32_t size)
此 FIR 数字滤波器函数,其中函数的自变量:*instance 此是指向 FIR 结构的指针,数字滤波器参数特性定义在此。输入*src 与输出*dst 是以 Q15 的数据格式来呈现,size 是此函数一次处理的取样数目,本实验的取样数目是 1024。
在使用此函数时,设计两种定义,一种是全部使用 Andes baseline 指令, 另一种使用 DSP 指令,D1088 除了具备一般 CPU 功能外,增加超过 130 DSP 相关指令。在此函数中除了运用 DSP Q 指令外也使用了DSP 中的saturation 运算, 当数字讯号运算后产生 overflow 或 underflow 时,没有使用 saturation 运算会产生错误且离谱的结果,Andes saturation 指令可以大大提升效能。
在 Fir_q15 函数在 D1088 上做验证函数的取样数目为 1024,在全部使用baseline 指令运算所得的 cycle 数除以取样数目 1024 得到每一笔 DSP 讯号所需要的 cycle 数是 210,如果使用 DSP 指令,处理每一笔 DSP 指令只需要的是 41 cycles。从 Fir_q15 函数运算结果得知 DSP 指令对比 baseline 指令运算效能提升5.12 倍。
1.2 DSP Benchmark 数值
下图[2]是依各类测试群组得到 D1088 与 Baseline CPU 的 benchmark 数据,总体 benchmark 的平均值 D1088/N1068 有 64%的性能提升:
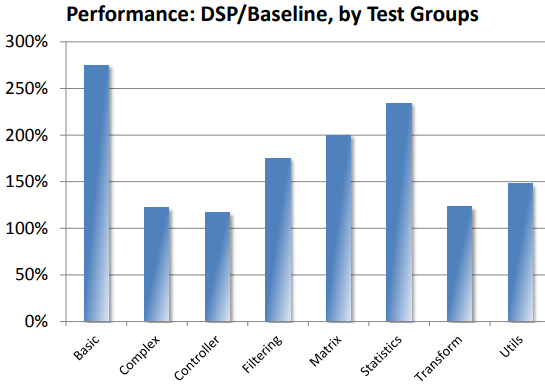
图 1. DSP Library 效能图
2. 车用电子产品需要通过之认证
近几年随着汽车市场逐步走向车联网、电动车领域,需要更多驾驶信息辅助整合系统,也让IC设计业者找到一个好的发展方向与新的产品市场。很明显, 车用电子要求有别于一般消费性产品,分别在产品的寿命,温度的范围,可靠度等级与安全性的要求等皆远高于消费性电子产品,车用电子需要经过ISO 26262 与AEC-Q100认证。晶心科技是CPU IP 的供货商,提供CPU IP给IC设计业者。从AEC-Q100的验证流程中,了解IC设计业在车用电子所在的角色,也可以得知CPU与IC设计业者在车用电子中的位置与关系。
2.1 车用IC规范AEC-Q100验证流程
图2为AEC-Q100规范中的验证流程[3],此图是以Die Design→Wafer Fab.→ PKG Assembly→Testing的制造流程来绘制,各群组的关联性须要参考图中的箭头符号,本文重点着重在IC设计业者(Design House),所以仅标示AEC-Q100中Design House与 Design Verification 相关测试项目。
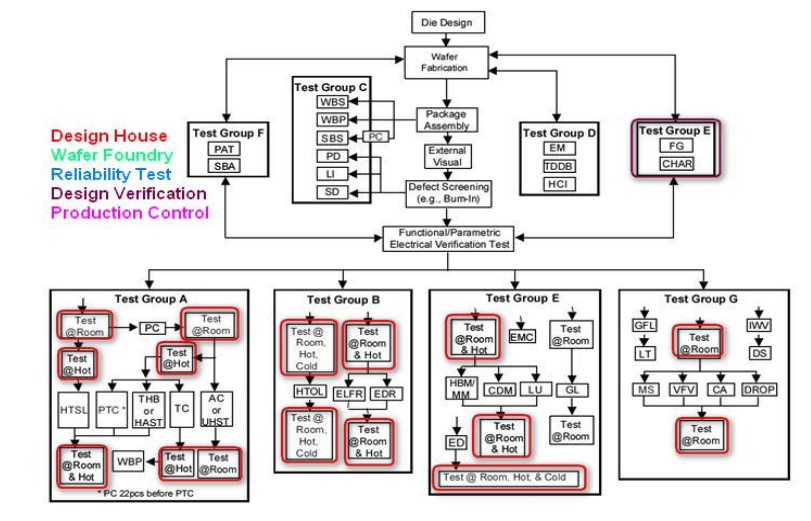
图 2. AEC-Q100 验证流程
2.2 IC设计业者进行AEC-Q100验证
在AEC-Q100建议中,IC设计业者需要依据IC芯片在汽车中使用位置区分为引擎区与乘坐区两部份,其基本工作环境要求不同,故对于测试温度,可靠度, 安全性的建议规格也不同。由于IC芯片种类繁多,因此在试验条件上,AEC-Q100 已进行分门别类,亦即依照属性设定建议的试验条件,当IC芯片设计测试规范订定后依据图2 AEC-Q100验证流程图,IC设计业者需完成红框的验证项目,当Wafer Foundry也通过需做测项后,AEC-Q100验证项目皆完成后,就可说此IC芯片完成AEC-Q100的验证。
3. 车用电子产品需要通过之认证
除了 ADAS 本身须具备之功能与通过 AEC-Q100 认证外,也需有额外设计才能符合在汽车的应用环境下的需求,下列几个实例说明在车用 ADAS 中增加的设计,有别于一般消费性电子产品。
3.1 CRC checksum 安全验证
在车用 ADAS 设计实例中,考虑到汽车环境中干扰严重且需要高可靠度。ADAS 程序在刻录进 ADAS 产品的 NOR-Flash 时, 将欲刻录程序经由CRC32-CCIR 演算后得到 32bits 结果一并写在 NOR-Flash 上。在车上当 ADAS 产品开机后,NOR-Flash 上的程序搬到 RAM 后,在 RAM 的程序也一样经过CRC32-CCIR 演算后得到的结果与程序后面 32bit checksum 演算结果做比对,如果 RAM 端与 NOR-Flash 数值一致表示通过 CRC checksum 安全验证,如果数值不一致代表 RAM 上的程序在过程中被干扰须采取对应的措施。增加 CRC checksum 安全验证可以知道车用 ADAS 对安全与可靠度要求远高于一般消费性电子产品。
3.2 程序启动前先行验证 CPU 周边
有别于一般消费性产品,车用电子产品在程序启动前需验证 CPU 周边device 本身之正确性,以 ADAS 实例来说明需要验证 cache 与 RAM。在 ADAS 程序执行前,提供晶心科技自定义指令集 CCTL (Cache Control)指令做 cache 的验证。将 CCTL 指令以 intrinsic 函数方式(如下所示)[4]提供给客户使用:
Unsigned int __nds32 cctlidx_read (const enum nds32_cctl_idxread subtype, unsigned int idx)
void __nds32 cctlidx_write (const enum nds32_cctl_idxwrite subtype, unsigned int b, unsigned int idxw)
开发 ADAS 客户使用晶心科技提供 nds32 cctlidx_write 函数写入 再用 _nds32 cctlidx_read 函數讀出來驗證整個 cache device。
RAM 在使用前也需要做 RAM device 的验证,进行 RAM device 验证需要验证程序结合 RAM 测试 pattern。晶心科技使用程序编写的技巧提供 ADAS 开发业者不需要用到RAM 的验证程序结合ADAS 开发业者使用March C Algorithm 做为的 RAM device 的验证 pattern。
在 ADAS 开机时使用 March C Algorithm 来做 RAM 的 BIST 好处是快速, 产品开机时所需的等待时间对于车用产品极为重要,也是车用产品优劣的重要评判准则,March C Algorithm 除了简单快速外,还有 fault coverage 高的特性。受到广泛的应用,将 March C Algorithm 的 pseudo code 详列如下[5]:
//for writing 0s in block 1 and writing 1s in block 2, let n and m are rows and columns for(i=0;i<(n-1)/2;i=i+1)
begin
for(j=0;j<(m-1);j=j+1)
mem[i][j]=0; //write 0 in m1
end
for(i=(n-1)/2;i<(n-1);i=i+1)
begin
for(j=0;j<(m-1);j=j+1)
mem[i][j]=1; //write 1 in m2
end
//for reading background and for writing alternate
for(i=0;i<(n-1)/2;i=i+1)
begin
for(j=0;j<(m-1);j=j+1)
begin
if(mem[i][j]==0)
mem[i][j]=1;
else return;
end
end
for(i=(n-1)/2;i<(n-1);i=i+1)
begin
for(j=0;j<(m-1);j=j+1)
begin
if(mem[i][j]==1)
mem[i][j]=0;
else return;
end
end
4. 结语
D1088 具 DSP 指令适合应用在于先进驾驶辅助系统。晶心科技提供高效能符合车用的 CPU 给 IC 设计业者,在 IC 设计业者开发车用 ADAS 产品时,晶心科技提供适当的支持协助 IC 设计业者开发具竞争力且符合车规之 ADAS 芯片与系统,衷心感谢伟诠公司顾朝奇博士与陈文庆先生的协助,才能完成此技术文章。
电子产业各项领域中,不论是 MCU,触控周边,IoT 与本文探讨之车用 ADAS, 晶心科技皆已取得不错的成效,也期望在未来趋势 ADAS 与车联网产业中晶心科技与我们的客户 IC 设计业者紧密的合作,开发出具竞争力的芯片与系统,达到双赢的目的。
参考文件
[1] Andes Fir_q15 Program “nds32_fir_q15.c”
[2] Andes Company Profile July 2016 page 28
[3] 新通讯 2016 年 4 月号 182 期《 技术前瞻 》
[4] Andes Programming Guide for ISA-V3 page 104
[5] Muddapu Parvathi , N. Vasantha, K. Satya Parasad, “Modified March C – Algorithm for Embedded Memory Testing” International Journal of Electrical and Computer Engineering (IJECE) Vol. 2, No.5, October 2012, pp. 571~576 ISSN: 2088-8708
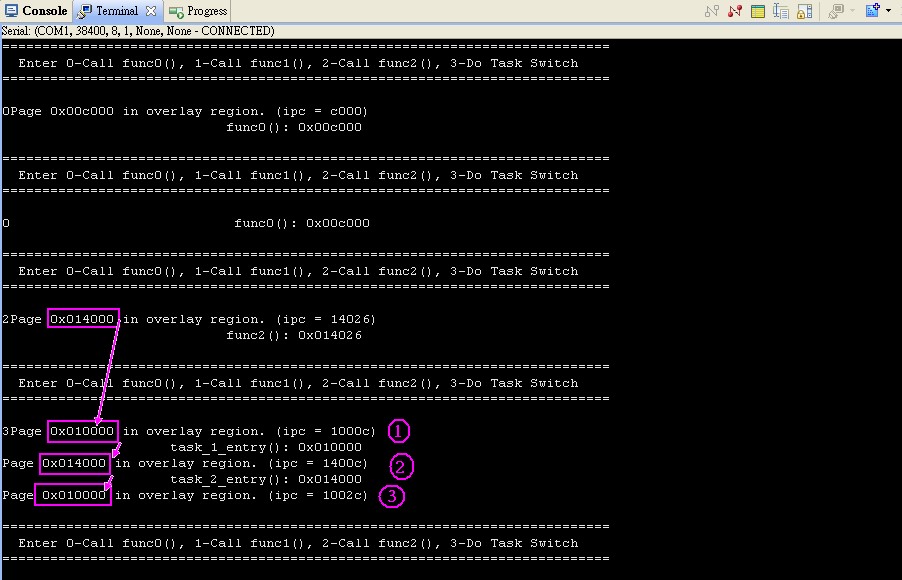
















 图表 2a. 指定函数放在自定义 section
图表 2a. 指定函数放在自定义 section 图表 2b. 指定函数放在自定义 section 的另一种写法
图表 2b. 指定函数放在自定义 section 的另一种写法 图表 3. 指定变量放在自定义 section
图表 3. 指定变量放在自定义 section 图表 4. ELF Header
图表 4. ELF Header 图表 5 指定 Vector table 到自定义 section
图表 5 指定 Vector table 到自定义 section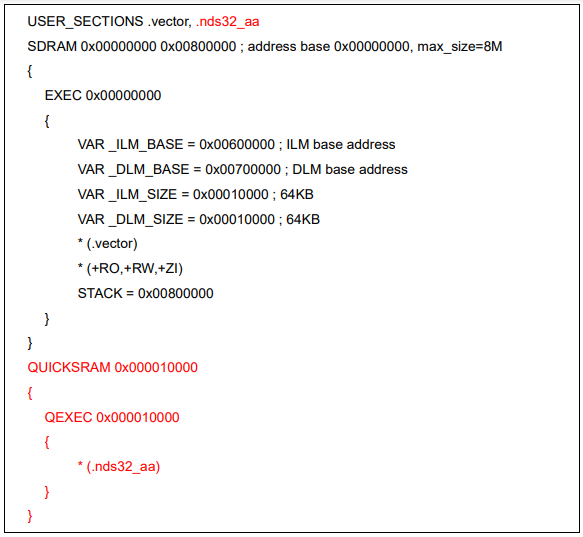 图表 6 指定自定义 section 到特定地址
图表 6 指定自定义 section 到特定地址 图表 7A 指定自定义 section 到特定地址
图表 7A 指定自定义 section 到特定地址
 图表 8 adx header
图表 8 adx header
 图表 9 “LMA_FORCE_ALIGN”example
图表 9 “LMA_FORCE_ALIGN”example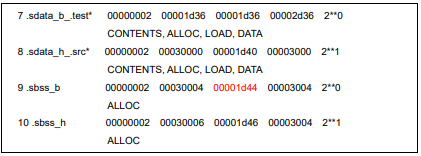 图表 10 “LMA_FORCE_ALIGN”的效果
图表 10 “LMA_FORCE_ALIGN”的效果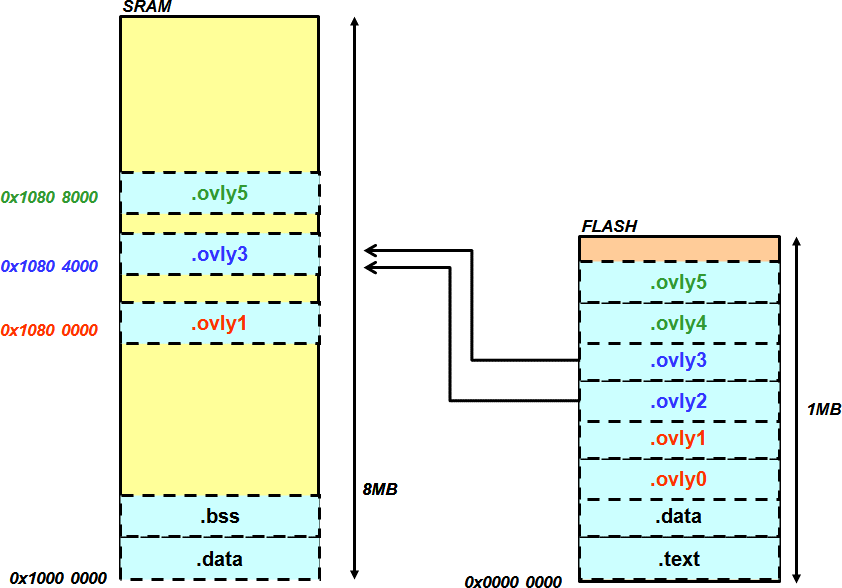
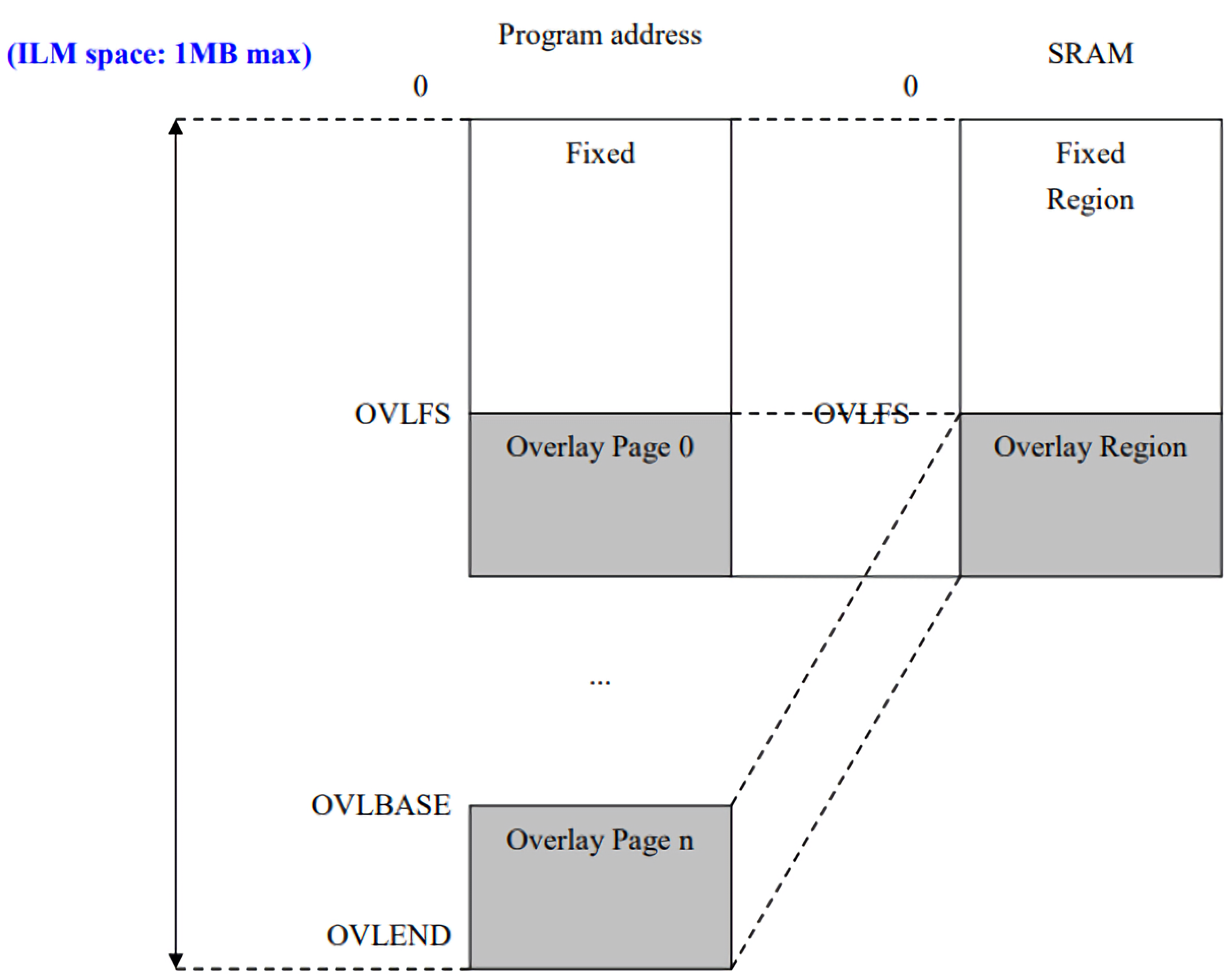
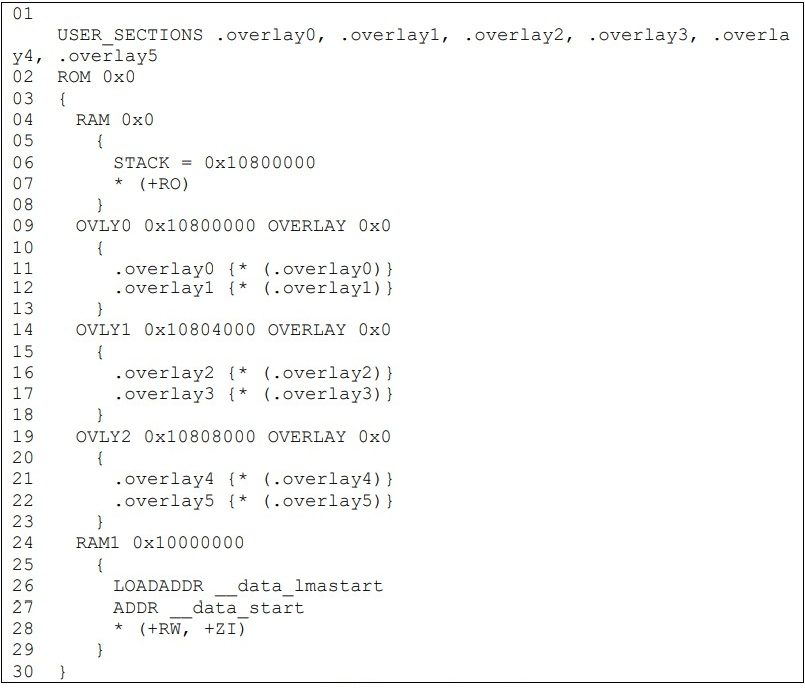 图表2. sw-ovly.sag文件
图表2. sw-ovly.sag文件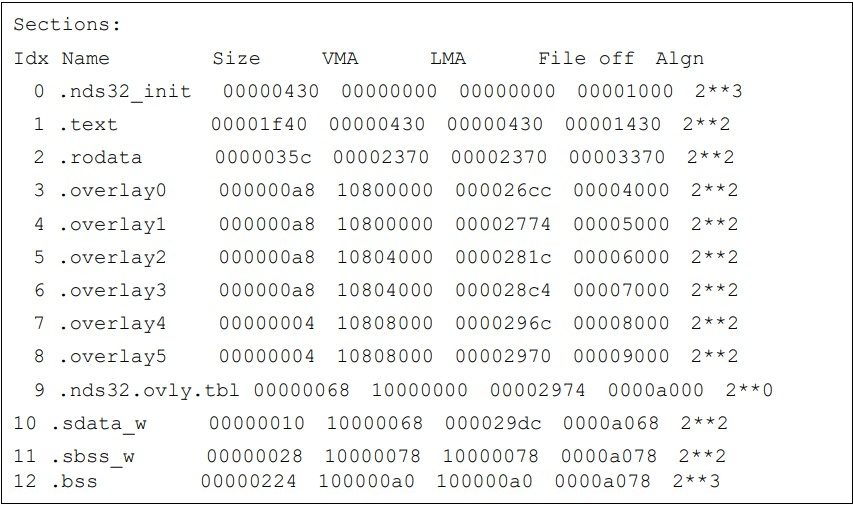 图表6. 各sections的LMA和VMA
图表6. 各sections的LMA和VMA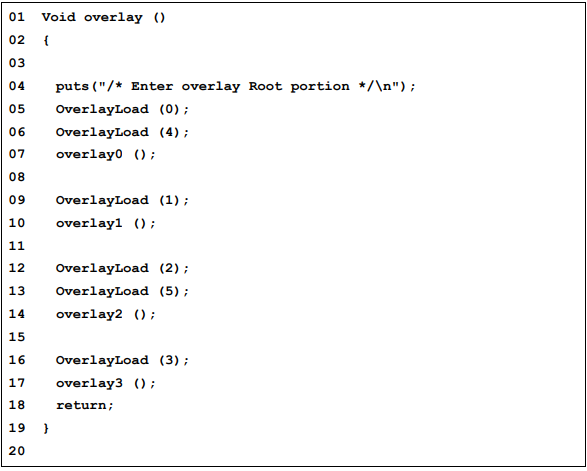 图表7. Overlay sections的使用方法
图表7. Overlay sections的使用方法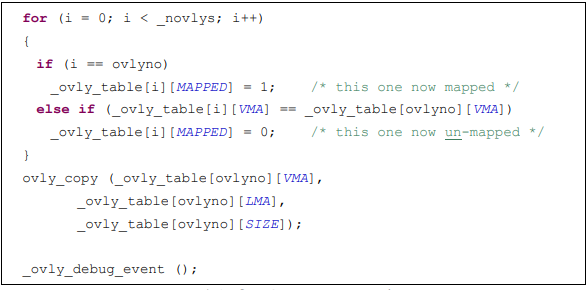 图表8. Overlay manager代码段
图表8. Overlay manager代码段 图表9. _ovly_table的内容
图表9. _ovly_table的内容










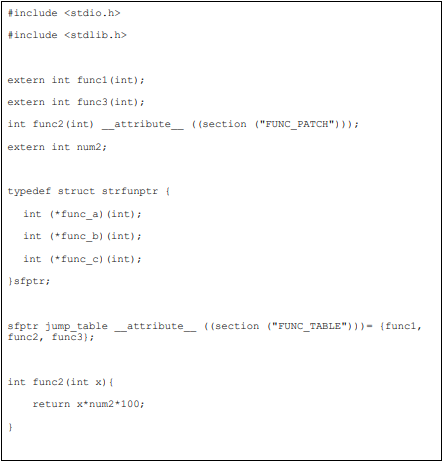
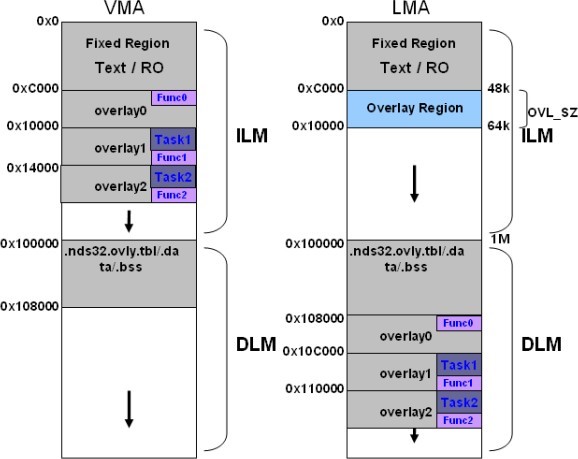
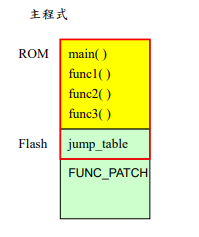 图表1 主程序的 memory layout 图
图表1 主程序的 memory layout 图


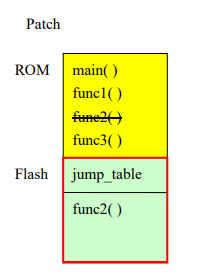 图表2 ROM patch 的 memory layout 图
图表2 ROM patch 的 memory layout 图 图表 3 主程序的 symbol
图表 3 主程序的 symbol