陈群旻,技术副理,晶心科技股份有限公司
AndesCore™除提供 AHP,APB ,HSMP 接口外,亦可透过 EILM 接口与内存整合,使 AndesCore™可以不透过 AMBA BUS 直接透过 EILM 接口撷取指令。然而嵌入式 Flash 的执行速度目前,并不能赶及 AndesCore™的工作频率, AndesCore™的执行效能将受限于嵌入式 Flash 的执行速度。此时可透过在 AndesCore™与 Flash 间的 EILM 接口之间加入一个预取模块,减少 AndesCore™因为 Flash throughput 跟不上 AndesCore™ 效能,使执行效能下降的影响。文章中所提供的参考预取模块,以 data width 32 bits 的 Flash 为操作对象,预取 buffer size 为两道 Instructions(32bits*2)提供一预取机制的设计参考。
本文之目的在提供与介绍一个预取模块的参考设计作为用户设计预取模块的参考。期望能对使用者有所帮助,也希望读者不吝指教提供您宝贵的意见。
1. Prefetch design 界面介绍
AndesCore™透过 EILM 接口可与外部 external local memory 整合,为了透过 Prefetch 模块根据前一道指令撷取时的地址,以 AndesCore™将循序撷取指令为预测逻辑来预取下道指令,并储存该指令内容于 Prefetch 模块,供 AndesCore™循序撷取指令时使用,我们将原本 AndesCore™与 EILM 的整合方式(如图一所示),改为在 AndesCore™与 EILM 之间加入 Prefetch 模块的整合方式(如图一所示)。
AndesCore™透过 EILM 接口跟 Prefetch 模块提交 request,Prefetch 模块透过 eilm_wait 告知 AndesCore™该 request 执行是否需要 wait,并在对应的时序提供 AndesCore™欲撷取的指令内容。
Prefetch 模块另有接口与 memory (Flash or ROM)整合,透过该接口进行对 memory 的读取。由于坊间 Flash or ROM 有各种 protocol,Andes 提供的 Prefetch reference design 主要专注于提供 prefetch 机制的参考设计,memory 接口以一 pseudo Flash 接口为设计对象,用户后续可根据所使用的 memory 的 protocol 进行调整设计。
1.1 Block Diagram

1.2 Signal Descriptions
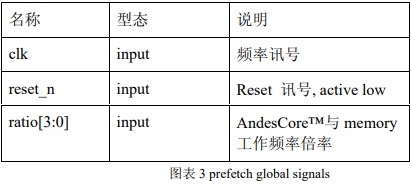
Prefetch 模块的 clock 与 reset,与 AndesCore™使用相同的 clock,reset 讯号源作设计,此外有一 input 讯号”ratio”用以设定 AndesCore™与 memory 工作频率倍率关系。其余讯号,我们分作两个群组”EILM”与”MEM”分别说明。
1.2.1. Global signals
1.2.2. EILM
Prefetch 模块透过 EILM 接口与 AndesCore™整合,依循 AndeStar 所定义的 protocol 与 AndesCore™沟通。

以下时序图说明 EILM 接口 Read/Write 时的讯号
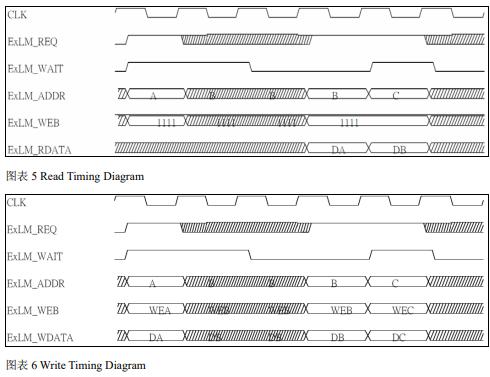
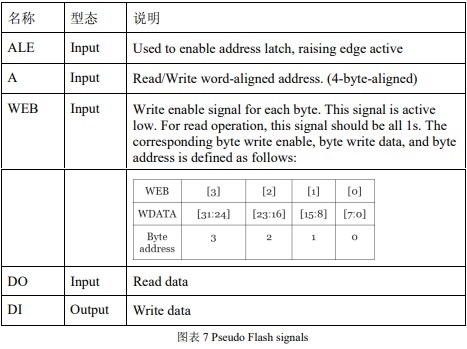
1.2.3. 本次仿真使用的 Flash 接口的讯号
Prefetch 模块的 memory 接口以一 pseudo Flash 接口为设计对象。并以此 memory 的 behavior module 与 Prefetch 模块整合后仿真。以下图表介绍此 pseudo Flash 之讯号与工作之时序。
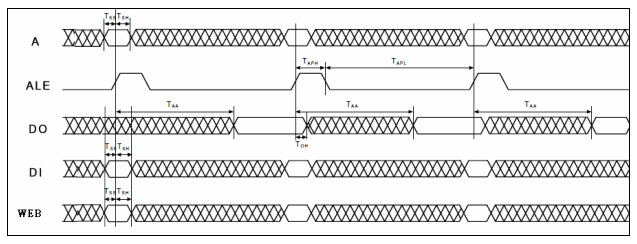 图表 8 Pseudo Flash Timing Diagram
图表 8 Pseudo Flash Timing Diagram
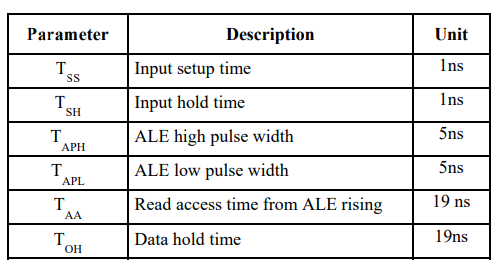 图表 9 Pseudo Flash AC Characteristics
图表 9 Pseudo Flash AC Characteristics
2. Prefetch 模块的主要功能介绍
透过 Prefetch 模块来提升 AndesCore EILM 撷取指令时的效率,减少 AndesCore 提出指令 request 后,等待 read data 自 Flash 回复有效值的等待时间,来增加 AndesCore 的执行效能。
实现方式是以前次 AndesCore 提出指令 request 时,所发出的 address 来预测后续 AndesCore 提出指令 request 的 address 为递增方式,在 AndesCore 提出指令 request 前,Prefetch 模块先将该递增 address 的指令内容由 Flash 取回并储存于 Prefetch 模块中,当 AndesCore 提出指令 request 的 address 确为递增方式,且指令内容已在 Prefetch 模块中,AndesCore 将不需 wait,可在下一时序即可自 Prefetch 模块撷取指令内容。
若 AndesCore 提出指令 request 的 address 为非递增方式,或是 AndesCore 提出指令 request 的频率高过 Prefetch 模块预取数据的频率,Prefetch 模块中已无事先预取的指令内容时,则依然透过 wait 讯号来延迟 AndesCore 撷取指令内容。
2.1 预取功能说明
图表 10 所示为 Prefetch 模块自 Flash 撷取指令内容的 function 示意图
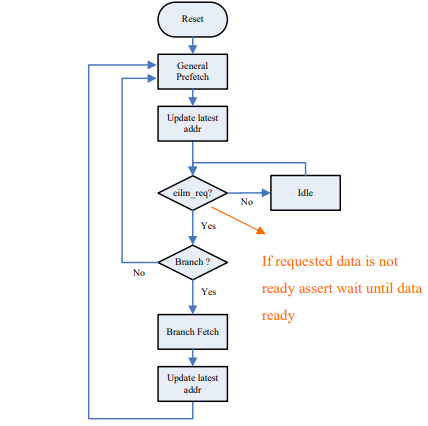
图表 10 Prefetch 模块自 Flash 撷取指令内容的 function 示意图
Reset 后, Prefetch 模块内并无预取的指令内容,于是执行 general prefetch function,后续当 AndesCore 提出指令 request 为递增方式,若指令已预取完成,则将指令内容传给 AndesCore,若指令预取未完成则拉 wait 讯号来延迟 AndesCore 撷取指令内容。再以目前 request 的 address 递增来预取指令。当 AndesCore 提出指令 request 不为递增方式(本文后续称为 branch),则拉 wait 讯号来延迟 AndesCore 撷取指令内容,同时 Prefetch 模块自 Flash 撷取该指令,当 Prefetch 模块得到有效数据时,撤回 wait 讯号,并将有效数据传给 AndesCore。再以目前 request 的 address 递增来预取指令。
2.2 主要程序说明
以下我们剪辑 Prefetch 模块 RTL 程序中几个重要部分来做说明
2.2.1 branch 判断:
当一个 AndesCore™ request (instruction fetch)被 Prefetch 模块接受时,若此 时的 address 不等于预设的递增 address,表示一个 branch 发生,Prefetch 模块将跟据 branch 时应有的动作来对 Flash 读取指令,使用 wait 讯号来延迟 AndesCore,选择 read data 等。
相关程序片断:
assign branch= eilm_read_req_valid&((lastest_eilm_ifetch_addr_inc1!=eilm_addr)|eilm_ifetch_n);
2.2.2 prefetch 判断:
当 Prefetch 模块处于 idle 状态时,若需要被预取的指令内容,未储存于 Prefetch 模块,则进行 prefetch 的动作,对 Flash 读取指令,并存放至 Prefetch 模块。 Prefetch 模块预取深度我们设计为 2,故我们会预取下一道 (lastest_eilm_ifetch_addr_inc1)及下下一道(lastest_eilm_ifetch_addr_inc2)指令。
相关程序片断:
assign prefetch_next1= (state_cnt==4’h0)& (~wait_for_write)&
(~((lastest_eilm_ifetch_addr_inc1==addr0)&addr0_valid )&
~((lastest_eilm_ifetch_addr_inc1==addr1)&addr1_valid ));
assign prefetch_next2= (state_cnt==4’h0)& (~wait_for_write)&
(~((lastest_eilm_ifetch_addr_inc2==addr0)&addr0_valid )&
~((lastest_eilm_ifetch_addr_inc2==addr1)&addr1_valid ));
2.2.3选择执行branch, prefetch 或 idle
当 Branch 发生时,不论需要被预取的指令内容是否已储存于 Prefetch 模块,执行 branch 时应有的动作,若有 prefetch 的动作执行中则放弃。
当Branch 未发生时,需要被预取的指令内容未储存于 Prefetch 模块,执行 prefetch时应有的动作,若需要被预取的指令内容已储存于 Prefetch 模块,Prefetch 模块处于 idle。
相关程序片断:

2.2.4 选择 read data:
若 Prefetch 模块处在执行 branch 时应有 function 的动作,自 Flash 于数据有效时撤回wait 讯号,选择 DO (Flash read data)作为响应给AndesCore 的read data。若 AndesCore 提出指令 request 为递增方式,则以预取的指令内容,作为响应给 AndesCore 的 read data。
相关程序片断:

2.2.5 储存预取的指令内容:
当进行 prefetch 的动作完成时,更新预取的指令内容。
A_latch 为进行 prefetch 的动作发 request 给 Flash 时所发出的 address,我们以 A_latch 最后一个位选择要储存于两个 buffer 中的哪一个。
相关程序片断:

2.3 波形圖說明
以下小节,为 After Reset, Branch, Sequential 三种状况下的波形图以及说明。![]()
2.3.1. After Reset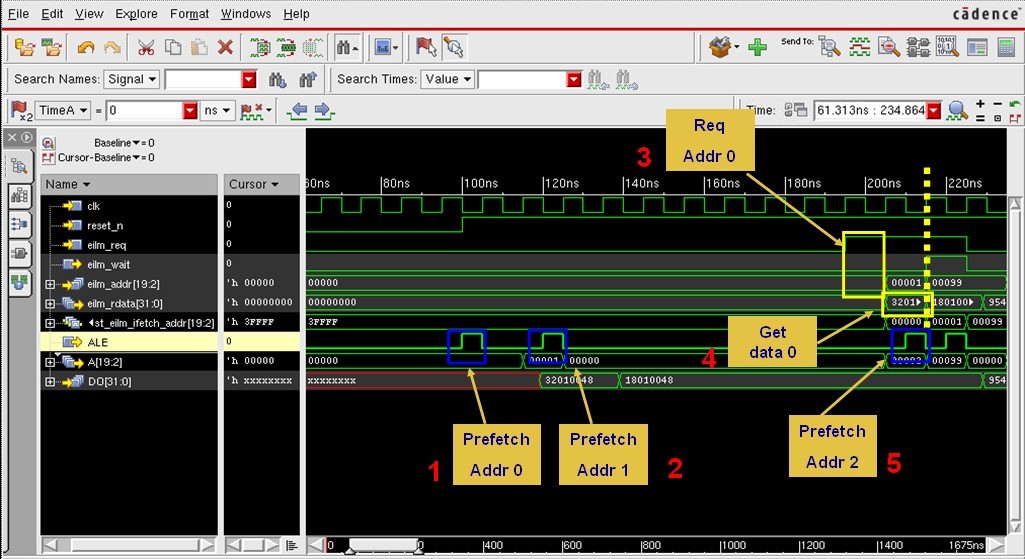
图表 11 After reset 波形图
波形图说明:

2.3.2. Branch fetch
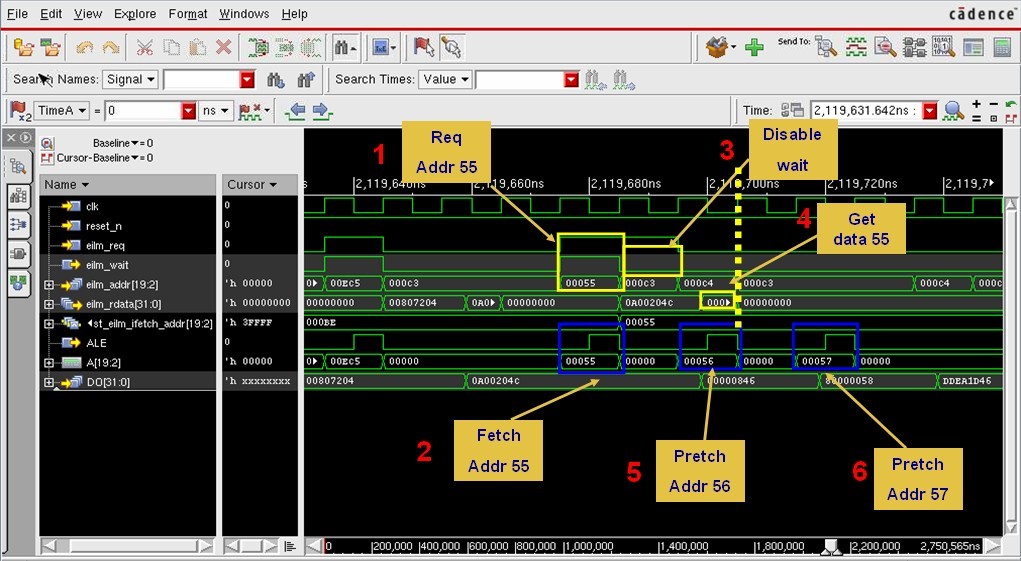
图表 12 branch fetch 波形图
波形图说明:

2.3.3. Sequential fetch
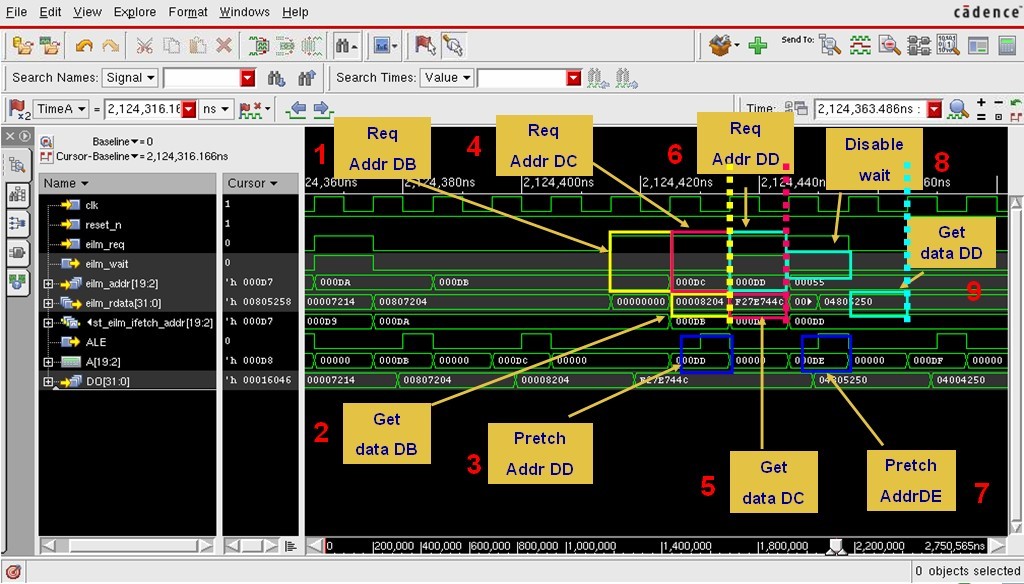
图表 13 sequential fetch 波形图
波形图说明:

3. Instruction fetch效能改善
由于参考模块,以 32 bits Flash 为设计对象,默认 AndesCore™ frequency 与 Flash frequency 为 n:1 (n≧2),Instruction fetch performance 受限 Flash 输出频率,故未能有明显提升。
当Flash 扩充带宽为64 bits,使Flash 输出及上AndesCore™指令消耗速度后, Instruction fetch performance 将会有明显提升。
Andes 已有客戶參考此設計,並加以修改,使之支援頻寬為 64 bits之Flash。以 AndesCore™ frequency 與 Flash frequency 為 2:1 下,由原本 fetch 一道指令平均需要兩 cycle 增進為 fetch 一道指令平均需要 1.1cycle。Instruction fetch 效能改善 80%左右。
Instruction fetch 效能改善可透过下列公式计算。
Instruction fetch performance improvement = ( 2/(1+ branch instruction ratio)
-1)*100%
(当branch 发生时,由于欲 fetch 的指令不在prefetch 内,此时仍需花费 2cycle fetch 该指令。)
4. 结语
AndesCore™所提供的 EILM 接口相当方便客户与 Flash 或 ROM 整合,然而 Flash 或 ROM 目前最高速 access time 目前不能与AndesCore™所能实现的最高工作频率相同。AndesCore™的执行效能将受限于 Flash 或 ROM 目前最高速 access time。Prefetch 模块提供一预取的机制来增加 AndesCore™与 Flash 或 ROM 整合时的执行效能。文章中所提供的参考预取模块,以 data width 32 bits 的 Flash 为操作对象,提供一预取机制的设计参考。使用者可参考此设计概念,将 data width 32 bits 的 Flash 为操作对象改为 data width 64 bits 的 Flash,在增加此设计后, Instruction fetch performance 将可得到符合使用者期待的效果。