Andes D1088 在汽車 ADAS之應用
沈智明,資深經理,晶心科技股份有限公司
先進駕駛輔助系統(Advanced Driver Assistance Systems;ADAS)為現今 IT 產業發展之重要方向,是將來可以達到無人駕駛智慧車輛的技術進階過程。ADAS 的主要功能並不是控制汽車,而是為駕駛人提供車內的工作情況與車外環境變化等相關資訊進行分析,提供預先警告可能的危險狀況,讓駕駛人提早採取因應措施,避免交通意外發生。晶心科技的產品 D1088 具數位信號處理器(digital signal processor,DSP)指令,除了一般 CPU 指令外還多了 SIMD instructions 來加速ADAS 系統的演算,增加 ADAS 產品之性能,也因此獲得客戶的認同使用晶心科技 D1088 開發 ADAS 產品。使用 D1088 開發的 ADAS 產品包括盲點偵測(Blind-Spot Detection, BSD),前車碰撞警示(Forward-Collision Warning, FCW),車道偏移警示(Lane-Departure Warning, LDW),移動物偵測(Motion-Object Detection, MOD),倒車碰撞警示(Rear-Collision Warning, RCW),行人碰撞警示(Pedestrian-Collision Warning, PCW)及行車紀錄器。
車 用 電 子 須 通 過 AEC-Q100(Automotive Electronics Council – Failure Mechanism Based Stress Test Qualification For Integrated Circuits)的認證,要求有別於一般消費性電子產品,本文之目的除了告訴我們的客戶(IC設計業者)D1088的優勢,也與我們的客戶一起探討車用電子與消費性電子產品間差異。希望在車用電子領域,晶心科技與我們的客戶攜手同行從今日開發ADAS晶片到未來的無人車自動駕駛。
1. D1088 應用於 ADAS 的優勢
生活環境中都是類比訊號,聲音是類比訊號,影像是類比訊號,汽車碰撞的壓力值還是類比訊號,汽車在行進中,感知器將量測數值傳送進 ADAS 控制器,經過 ADC 轉換後得到數位訊號﹐車內外環境中充滿了干擾與雜訊,濾波器可以濾掉雜訊與干擾,大大提升訊號正確性與可靠度,還原事物的原貌。文中以數位濾波器 FIR (Finite Impulse Response)為例,比較使用一般 CPU 指令與D1088 提供的 DSP 指令在實踐 FIR 時的差異,說明 D1088 的優勢與特性。
1.1 使用Fir_q15 函數驗證
以 ADAS 中車道偏移警示系統會用到的 FIR 數位濾波器,使用 Fir_q15[1] 函數 C 語言實作如下所示:
void nds32_fir_q15(const nds32_fir_q15_t *instance,q15_t *src, q15_t *dst, uint32_t size)
此 FIR 數位濾波器函數,其中函數的引數:*instance 此是指向 FIR 結構的指標,數位濾波器參數特性定義在此。輸入*src 與輸出*dst 是以 Q15 的資料格式來呈現,size 是此函數一次處理的取樣數目,本實驗的取樣數目是 1024。
在使用此函數時,設計兩種定義,一種是全部使用 Andes baseline 指令, 另一種使用 DSP 指令,D1088 除了具備一般 CPU 功能外,增加超過 130 DSP 相關指令。在此函數中除了運用 DSP Q 指令外也使用了DSP 中的saturation 運算, 當數位訊號運算後產生 overflow 或 underflow 時,沒有使用 saturation 運算會產生錯誤且離譜的結果,Andes saturation 指令可以大大提升效能。
在 Fir_q15 函數在 D1088 上做驗證函數的取樣數目為 1024,在全部使用baseline 指令運算所得的 cycle 數除以取樣數目 1024 得到每一筆 DSP 訊號所需要的 cycle 數是 210,如果使用 DSP 指令,處理每一筆 DSP 指令只需要的是 41 cycles。從 Fir_q15 函數運算結果得知 DSP 指令對比 baseline 指令運算效能提升5.12 倍。
1.2 DSP Benchmark 數值
下圖1是依各類測試群組得到 D1088 與 Baseline CPU 的 benchmark 數據,總體 benchmark 的平均值 D1088/N1068 有 64%的性能提升:
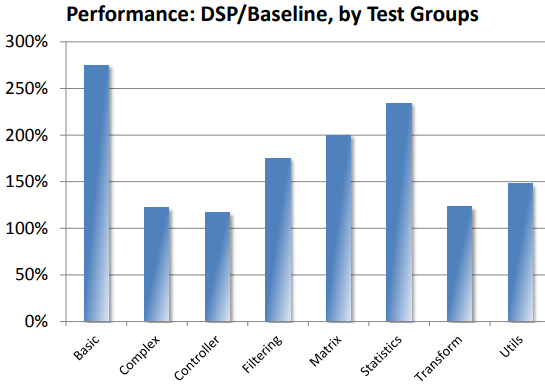
圖1 DSP Library效能圖
2. 車用電子產品需要通過之認證
近幾年隨著汽車市場逐步走向車聯網、電動車領域,需要更多駕駛資訊輔助整合系統,也讓IC設計業者找到一個好的發展方向與新的產品市場。很明顯, 車用電子要求有別於一般消費性產品,分別在產品的壽命,溫度的範圍,可靠度等級與安全性的要求等皆遠高於消費性電子產品,車用電子需要經過ISO 26262 與AEC-Q100認證。晶心科技是CPU IP 的供應商,提供CPU IP給IC設計業者。從AEC-Q100的驗證流程中,了解IC設計業在車用電子所在的角色,也可以得知CPU與IC設計業者在車用電子中的位置與關係。
2.1 車用IC規範AEC-Q100驗證流程
圖2為AEC-Q100規範中的驗證流程[3],此圖是以Die Design→Wafer Fab.→ PKG Assembly→Testing的製造流程來繪製,各群組的關聯性須要參考圖中的箭頭符號,本文重點著重在IC設計業者(Design House),所以僅標示AEC-Q100中Design House與 Design Verification 相關測試項目。
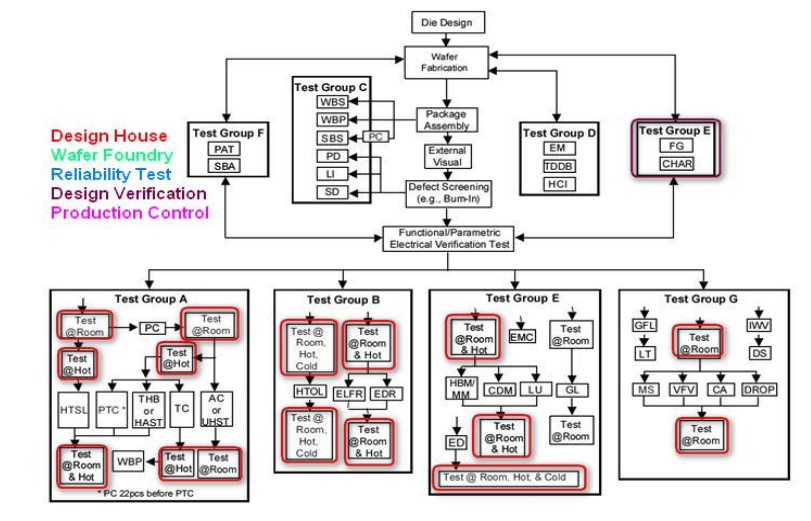
圖 2. AEC-Q100 驗證流程
2.2 IC設計業者進行AEC-Q100驗證
在AEC-Q100建議中,IC設計業者需要依據IC晶片在汽車中使用位置區分為引擎區與乘坐區兩部份,其基本工作環境要求不同,故對於測試溫度,可靠度, 安全性的建議規格也不同。由於IC晶片種類繁多,因此在試驗條件上,AEC-Q100 已進行分門別類,亦即依照屬性設定建議的試驗條件,當IC晶片設計測試規範訂定後依據圖2 AEC-Q100驗證流程圖,IC設計業者需完成紅框的驗證項目,當Wafer Foundry也通過需做測項後,AEC-Q100驗證項目皆完成後,就可說此IC晶片完成AEC-Q100的驗證。
3. 車用電子產品需要通過之認證
除了 ADAS 本身須具備之功能與通過 AEC-Q100 認證外,也需有額外設計才能符合在汽車的應用環境下的需求,下列幾個實例說明在車用 ADAS 中增加的設計,有別於一般消費性電子產品。
3.1 CRC checksum 安全驗證
在車用 ADAS 設計實例中,考慮到汽車環境中干擾嚴重且需要高可靠度。ADAS 程式在燒錄進 ADAS 產品的 NOR-Flash 時, 將欲燒錄程式經由CRC32-CCIR 演算後得到 32bits 結果一併寫在 NOR-Flash 上。在車上當 ADAS 產品開機後,NOR-Flash 上的程式搬到 RAM 後,在 RAM 的程式也一樣經過CRC32-CCIR 演算後得到的結果與程式後面 32bit checksum 演算結果做比對,如果 RAM 端與 NOR-Flash 數值一致表示通過 CRC checksum 安全驗證,如果數值不一致代表 RAM 上的程式在過程中被干擾須採取對應的措施。增加 CRC checksum 安全驗證可以知道車用 ADAS 對安全與可靠度要求遠高於一般消費性電子產品。
3.2 程式啟動前先行驗證 CPU 周邊
有別於一般消費性產品,車用電子產品在程式啟動前需驗證 CPU 周邊device 本身之正確性,以 ADAS 實例來說明需要驗證 cache 與 RAM。在 ADAS 程式執行前,提供晶心科技自訂指令集 CCTL (Cache Control)指令做 cache 的驗證。將 CCTL 指令以 intrinsic 函數方式(如下所示)[4]提供給客戶使用:
Unsigned int __nds32 cctlidx_read (const enum nds32_cctl_idxread subtype, unsigned int idx)
void __nds32 cctlidx_write (const enum nds32_cctl_idxwrite subtype, unsigned int b, unsigned int idxw)
開發 ADAS 客戶使用晶心科技提供 nds32 cctlidx_write 函數寫入 再用 nds32 cctlidx_read 函數讀出來驗證整個 cache device。
RAM 在使用前也需要做 RAM device 的驗證,進行 RAM device 驗證需要驗證程式結合 RAM 測試 pattern。晶心科技使用程式編寫的技巧提供 ADAS 開發業者不需要用到RAM 的驗證程式結合ADAS 開發業者使用March C Algorithm 做為的 RAM device 的驗證 pattern。
在 ADAS 開機時使用 March C Algorithm 來做 RAM 的 BIST 好處是快速, 產品開機時所需的等待時間對於車用產品極為重要,也是車用產品優劣的重要評判準則,March C Algorithm 除了簡單快速外,還有 fault coverage 高的特性。受到廣泛的應用,將 March C Algorithm 的 pseudo code 詳列如下[5]:
//for writing 0s in block 1 and writing 1s in block 2, let n and m are rows and columns for(i=0;i<(n-1)/2;i=i+1)
begin
for(j=0;j<(m-1);j=j+1)
mem[i][j]=0; //write 0 in m1
end
for(i=(n-1)/2;i<(n-1);i=i+1)
begin
for(j=0;j<(m-1);j=j+1)
mem[i][j]=1; //write 1 in m2
end
//for reading background and for writing alternate
for(i=0;i<(n-1)/2;i=i+1)
begin
for(j=0;j<(m-1);j=j+1)
begin
if(mem[i][j]==0)
mem[i][j]=1;
else return;
end
end
for(i=(n-1)/2;i<(n-1);i=i+1)
begin
for(j=0;j<(m-1);j=j+1)
begin
if(mem[i][j]==1)
mem[i][j]=0;
else return;
end
end
4. 結語
D1088 具 DSP 指令適合應用在於先進駕駛輔助系統。晶心科技提供高效能符合車用的 CPU 給 IC 設計業者,在 IC 設計業者開發車用 ADAS 產品時,晶心科技提供適當的支援協助 IC 設計業者開發具競爭力且符合車規之 ADAS 晶片與系統,衷心感謝偉詮公司顧朝奇博士與陳文慶先生的協助,才能完成此技術文章。
電子產業各項領域中,不論是 MCU,觸控周邊,IoT 與本文探討之車用 ADAS, 晶心科技皆已取得不錯的成效,也期望在未來趨勢 ADAS 與車聯網產業中晶心科技與我們的客戶 IC 設計業者緊密的合作,開發出具競爭力的晶片與系統,達到雙贏的目的。
參考文件
[1] Andes Fir_q15 Program “nds32_fir_q15.c”
[2] Andes Company Profile July 2016 page 28
[3] 新通訊 2016 年 4 月號 182 期《 技術前瞻 》
[4] Andes Programming Guide for ISA-V3 page 104
[5] Muddapu Parvathi , N. Vasantha, K. Satya Parasad, “Modified March C – Algorithm for Embedded Memory Testing” International Journal of Electrical and Computer Engineering (IJECE) Vol. 2, No.5, October 2012, pp. 571~576 ISSN: 2088-8708
晶心平台運行具 OSC 的 FreeRTOS
沈智明,資深經理,晶心科技股份有限公司
晶心科技所設計 IP 的目的,是滿足客戶實際需求,提供低成本高效率的產品給客戶,讓客戶可以做出極具競爭力的SoC,達到客戶與晶心科技雙贏的目的, 本文介紹的具 OSC 的 FreeRTOS 產品,巧妙的與 AndesCore™結合,客戶導入產品後,具競爭力與實用性,本文的目的期望能夠讓更多的讀者清楚這個產品的特性與優勢進而使用此產品。
某些電子產品的應用是不同的時間需要運行不同的功能,這時需要大空間的ROM 與 RAM 來存放與運行時會用到的各式各樣的功能。因為 CPU 同時間只會運行一種功能。所以在務實與經濟的考量下可以使用 overlay 的方式來滿足此類型產品的需求, 不但大幅降低 RAM 空間的使用,也達成硬體成本降低,使得產品競爭力大大的提升。達成 overlay 的方式有兩種,純軟體 overlay 與硬體加速 overlay。純軟體的 overlay 不須增加硬體,但軟體工程師寫程式時需自己配置functions 擺放的位置,容易出錯;呼叫 functions 時需要經過額外的處理,降低程式效能。因此純軟體的方法多用於只需偶而更換 overlay 的應用。例如 audio player,一條歌播完下一條開始前才需要檢查是否要用不同 decoder。我们有另一篇文章針對軟體 overlay 做介绍,本文不多加探討。
硬體加速的 overlay 使用少許硬體 gate count < 2K (OSC, Overlay SRAM Controller),提供軟體透明的 overlay 處理。軟體工程師寫程式時,可以假設有一個很大的連續程式空間,完全不需配置 functions 擺放的位置,這大大增加開發程式的效率;同時,呼叫 functions 時完全沒有任何純軟體方式的 overhead。上述之 OSC 優點可以符合客戶之需求,如果客戶系統複雜,要做的事比較多,需要用到多工(Multi-tasking),則晶心科技「支援 OSC 的 FreeRTOS 產品」就是最佳解方案。
1. Andes OSC 工作原理
先設定AndesCore™ NCEOSC100 IP中暫存器,再與運行軟體做整合搭配, 即可執行OSC的功能。
1.1 設定 OSC IP 的暫存器與動作解說
• OSC Control Register, OSCCTRL (+0x00)
• OVL_SZ: 3’h4 (16KB) RO/WI
• OVL_VALID: 0
• Fixed Region Size Register, OVLFS (+0x04)
• OVL_FSZ: 8’h18 (96KB) RW
• Overlay Region Base Register, OVLBASE (+0x08)
• Overlay Region End Register, OVLEND (+0x0C)
在OSC設計中SRAM分為兩個區域一個是”fixed region” 另一個是 “overlay region”,fixed region 為低位址的 SRAM ,其大小由OVLFS 暫存器設定。overlay region 是一個動態的區域,其位址由OVLBASE暫存器設定,大小由OVL_SZ 設定。當CPU運行時存取位址落在暫存器 OVLBASE與OVLEND之間時OSC將自動轉址到SRAM的overlay region內,如圖1所示。
因應實際需求設定多個Overlay 區域,當發生 ”Overlay Miss” 時,經由Overlay Exception的機制與軟體的搭配,可以將storage 中的 overlay page N 複製到 SRAM 中的Overlay Region,如圖1所示。關於overlay page 置換的工作原理將於下兩個章節中做說明。
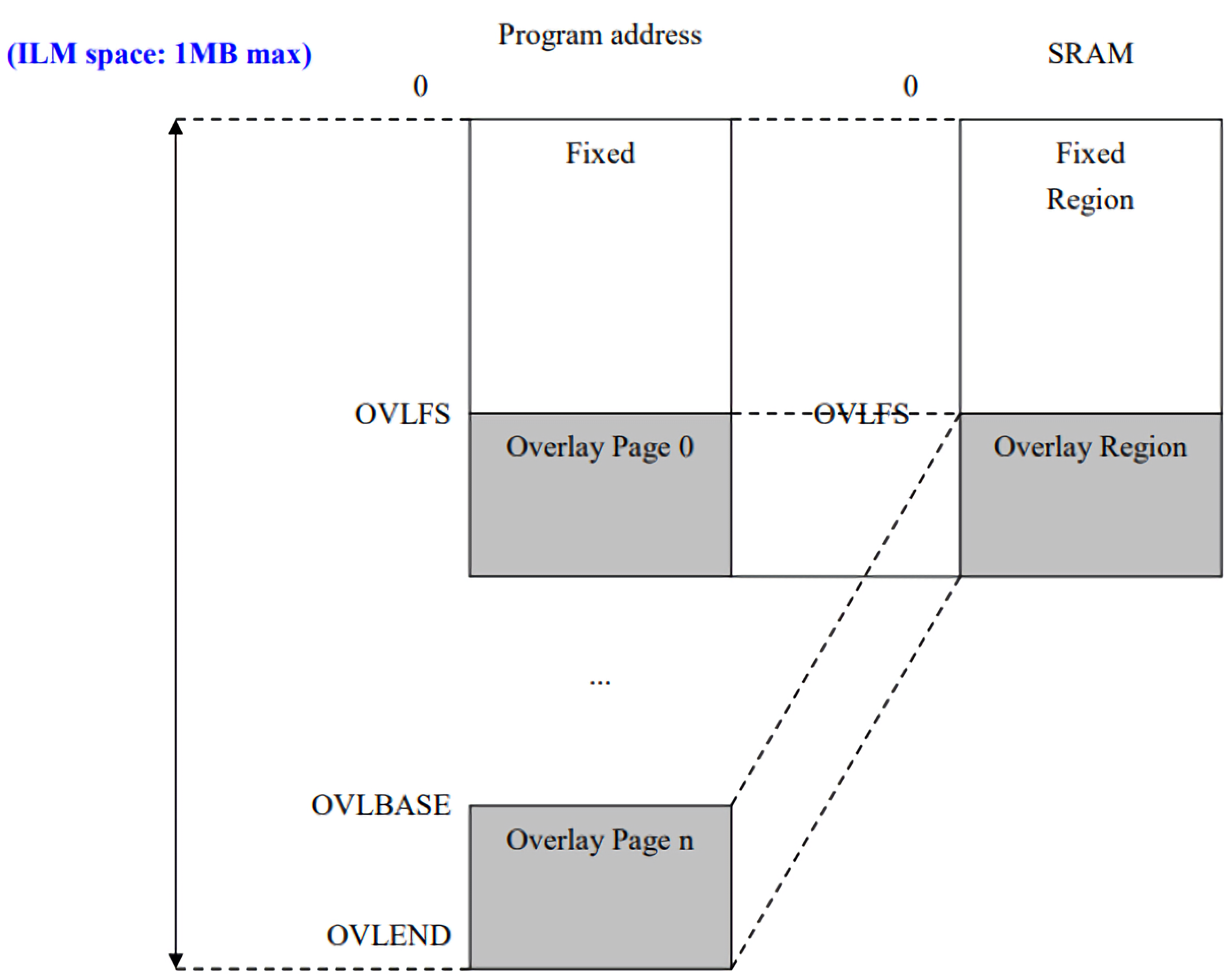
圖 1. Overlay 範例說明
CPU運行時存取位址不在fixed region 或是當時有效的 overlay page 時,會發生Overlay Miss。當o Miss 發生時OSC會產生illegal instruction (32’hcoddcodd) 造成general exception。因為也有其他原因也會產生general exception,如何區分出overlay miss 與其他general exception於下個章節說明。
1.2 Overlay Exception 偵測
當進入 general exception 時可透過軟體檢驗下列程序來判斷是否為overlay
miss:
Step 1 如果 interrupt level 已經到達最大值 (PSW.INTL == Max INTL) ,這是 fetal error 不是overlay miss。
Step 2 必須是ITYPE.EYPE==1,才有機會是overlay miss。
Step 3 檢查IPC值,如果是落在fixed region 或是當時有效的 overlay page 時,這是真正的 illegal exception case. 如果不是在這兩個區域則是overlay miss。
經過前面3步驟驗證,如果確定是overlay miss,則可進行Overlay exception handling 的動作。
1.3 執行 Overlay Exception Handling 的動作
確定 overlay miss 後,做更新overlay region的動作。
Step 1 得到新的overlay region 位址:
– 從IPC得到更新overlay page的起始位置。
– 更新OVLBASE 暫存器。
Step 2 更新的overlay page內容複製到 SRAM 中的overlay region
Step 3 最後執行iret返回overlay miss發生時的位址。
2. 具 OSC 的 FreeRTOS 介紹
Andes 結合OSC 與 FreeRTOS設計出具 OSC的FreeRTOS ,OSC的功能與原理已經介紹於上個章節,本章節將說明具 OSC的FreeRTOS與一般的FreeRTOS 的差異處,並列舉範例程式的運行展現OSC與FreeRTOS的功能。
2.1 具OSC的FreeRTOS記憶體配置
具OSC的FreeRTOS的記憶體配置如圖2 , 範例程式的linker script設定了LMA(系統image)的記憶體配置模式,其中overlay0, overlay1 與 overlay2是模擬storage 的位址。linker script 設定VMA(系統執行時)的記憶體配置模式,當系統運行進入overlay1,2.. 時產生overlay miss 觸發 exception 將overlayN 內的資料複製到 overlay region 中,這樣的設計達到一份Overlay Region 的SRAM空間可以在不同時間執行對應不同的overlayN程式碼的目的。
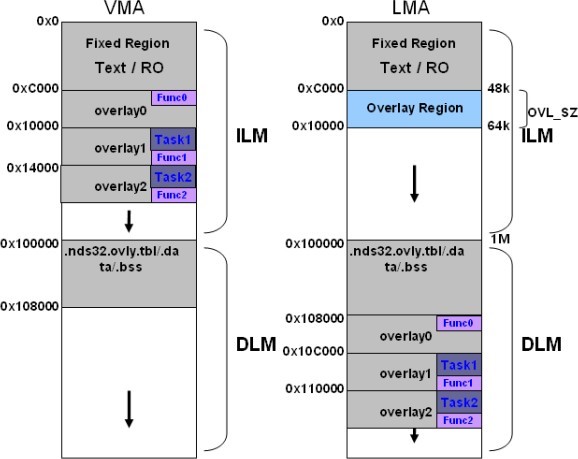
圖 2.具 OSC 的 FreeRTOS 記憶體配置圖
2.2 osc_hisr task
從圖2的overlay0,1,2 中可以發現系統會運行task1與task2。說明FreeRTOS 做overlay region置換時也會執行scheduler 做置換task 的工作。本範例程式設計是在standard FreeRTOS 中增加一個 osc_hisr task 做overlay region 置換與管理的工作。如何達到OSC 與 osc_hisr task的結合需從Overlay Exception Handling的動作開始研討:
• 當 overlay exception 被觸發時,送 message 給 queue 啟動 osc_hisr task。
• 因為 osc_hisr task 做 overlay region 資料的置換,所以 osc_hisr task 尚未執行完成前,不可以執行 Overlay Exception Handling 的 iret.
osc_hisr task 的主要工作在:
• Map overlay region
• overlay region 資料的複製
osc_hisr task 設計的原則:
• 此 task 必須是最高 priority task.
• 此 task 必須放在 fixed region.
2.3 範例程式運行
具 OSC 的 FreeRTOS 在 Andes EVB 上直接運行得到的結果如圖 3,範例程式中鍵入 3 時,是進行 task 轉換,因為不同 task 運行相對應的 overlay function 從console task 轉成task1 再轉成task2 也會產生相對應的page fault 執行osc_hisr task。圖 3 紅色箭頭與數字轉變可以得知 task 轉換啟動 function overlay 運作,從此範例程式中可同時驗證 OSC 與 FreeRTOS 兩者的功能。
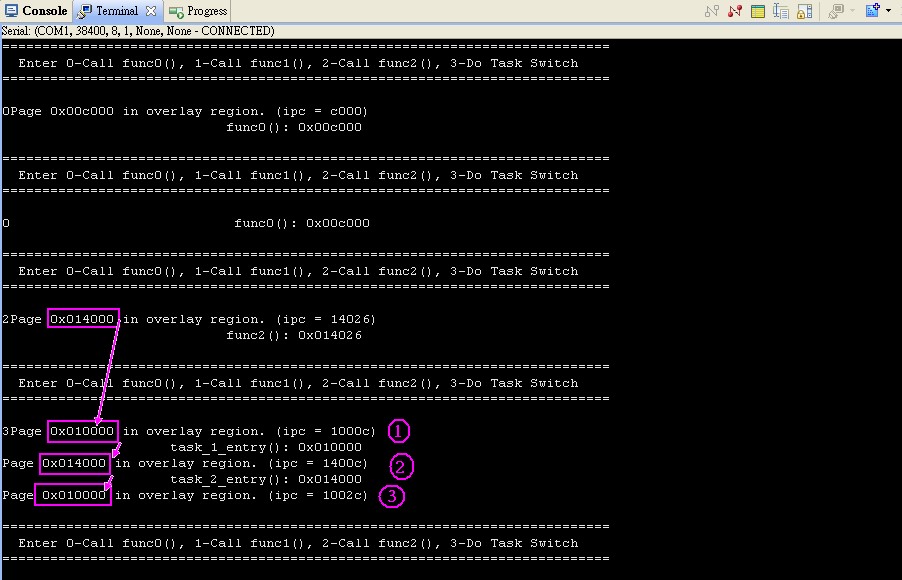
圖 3.範例程式執行結果
3. 結語
本文第一章說明 Andes OSC 的工作原理與功能,第二章說明 FreeRTOS 如何與 Andes OSC 整合運作,在 OSC 的 FreeROTS 中也增加一個最高 priority task “osc_hisr” 來執行 OSC 相對應的功能,進而說明了具 OSC 的 FreeRTOS 需注意的設計原則,具 OSC 之 FreeRTOS 是由軟體與硬體單元所組成,兼具硬體的效能與軟體的彈性。
已經有業界客戶取得 Andes 的具 OSC 之 FreeRTOS 開發出具競爭力產品在市面上銷售,由此可知具 OSC 之 FreeRTOS 具有經濟實用的價值,可以協助客戶在使用 AndesCore™時,設計出具有彈性且高附加價值之產品。
8051 與 AndesCore™ 的軟體差異與移植
1. 8051 與 AndesCore™
本文將介紹使用 8051 與 AndesCore™差異事項,並對兩種 CPU 系統相關事項做說明,後面再介紹從 8051 移植到 AndesCore™上注意事項,舉中斷向量表及異常處理函數的例子說明差異及移植,最後簡要介紹 AndesCore™在 MCU 應用的三款 CPU: N705,N801 和 N968A。
2. 8051 與 AndesCore™ 常見差異事項
2.1. 位寬的差異
位元寬是指處理器一次執行指令的資料頻寬。8051 是 8 位寬的處理器, 而AndesCore™是 32 位寬的處理器,支援 32 位與 16 位元的混合指令集,位元數越寬,在資料的處理方面就更有效率。

2.2. 指令差異
8051 組合語言共有 111 條指令集,AndeStar™的 V3m 指令集有 157 條, AndeStar™的 V3 指令集有 200 多條,兩種 CPU 的指令集大概可以分為以下幾類:算數運算,如加,減,乘,除等操作;資料傳送,如數據在暫存器與記憶體間的傳送,賦值等;邏輯跳轉,如函數呼叫,無條件跳轉,條件跳轉,中斷返回等;在AndesCore™中還有特權模式的指令部分,關於兩種指令集的具體差別, 可以分別參考對應的指令集介紹文檔。
2.3. 位址空間映射差異
AndesCore™使用 memory map 方式映射位址空間,主要有兩種,記憶體的空間映射,如其中的 RAM 或 ROM 位址,它們用於存放程式運行時的代碼和資料,在 AndesCore™上代碼在 link 後,程式運行的代碼和資料位址會最終確定, Andes 提供了一個簡便的 link script 工具 SaG,可以很方便的對系統中可用的記憶體空間進行分配設定。
另一個是週邊所對應的位址空間,可以通過查看 SoC 對應的手冊瞭解對應的週邊映射的空間範圍及相應的使用方法。
2.4. 堆疊設置差異
8051 的堆疊的起始位置是固定的(部分衍生 8051 可以做程式設定),它通常固定在晶片內的 RAM 中,8051 記憶體空間有限,非常小,程式中所使用的變數存放於特定的資料空間中,並不會放在堆疊空間,所以在 8051 中所需要的堆疊空間很小。而對於AndesCore™來說,堆疊可以設置在任意合適的RAM 上。程式運行時所有的區域變數都存放在堆疊中,只需要確保在設計系統的時候有足夠的堆疊空間。在 AndesCore™中有$sp 暫存器記錄堆疊位置,這需要在系統上電或者是系統 reset 後初始化時進行設置。
2.5. 代碼和資料的存儲差異
在 8051 系列單晶片中,資料存儲區可以分為內部資料存儲區以及外部資料存儲區。
內部資料存儲區有幾個區域:data,bdata,idata。
data : 片內 RAM 直接定址區。bdata: 片內 RAM 位定址區。idata: 片內 RAM間接定址區。
外部資料存儲區又有:xdata,pdata。
xdata 和 pdata:是外部存儲區,有些晶片會帶有 XRAM。
在有些開發工具中,如 Keil,可以通過設置存儲模式來處理,存儲模式決定了預設的記憶體類型,此記憶體類型將應用於函數參數,區域變數和定義時未包含記憶體類型的變數。
SMALL 所有的變數存放在片內 RAM(data 區間)
COMPACT 所有的變數存放在外部存儲區(pdata 區間)
LARGE 所有的變數存放在外部存儲區(xdata 區間)
AndesCore™以記憶體映射的方式,記憶體空間不會有特別的限制,就是說不會像 8051 那樣需放在某處區間,這樣的設計更方便靈活,允許程式碼和資料在可用的空間裡自由放置。
有時候需要將某段代碼或者資料存放在指定的位置上,在 8051 中,可以在代碼中使用”at”關鍵字,但該關鍵字是 8051 中所特有的,會造成可攜性和維護的問題,在 AndesCore™上,提供了一種簡便的 link script 工具,如上所提到的SaG 工具,在 C 代碼中使用 GNU 標準的語法格式,在 link 之後相應的代碼和資料將存放於指定的位置,這樣可以避免在代碼中使用”at”該平臺相關的屬性設置。
2.6. 資料類型及對齊差異
8051 和 AndesCore™是不同類型的CPU,它們所使用的資料類型所對應的寬度也不同,如下表所示:
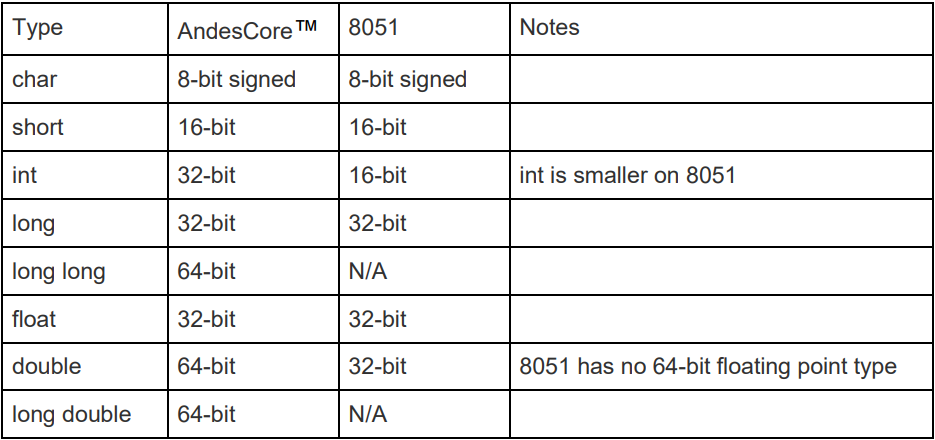
在連結完成後資料通常都會按照本身的屬性對齊,比如 int 類型則會 4 bytes 對齊,short 則會 2 bytes 對齊。這樣的存放方式可以提高 CPU 對資料讀取時的效率。雖然 AndesCore™是 32bit 的 CPU, 在只需要 8bit 和 16bit 的資料時能節省存儲空間,但在處理 16bit 和 32bit 的資料上則有更高效。
在 8051 中有 sbit 關鍵字用於設置對特殊功能暫存器 SFR 的直接 access, 8051 的特殊功能暫存器分佈在記憶體位址 0x80 到 0xFF 處,如下表:
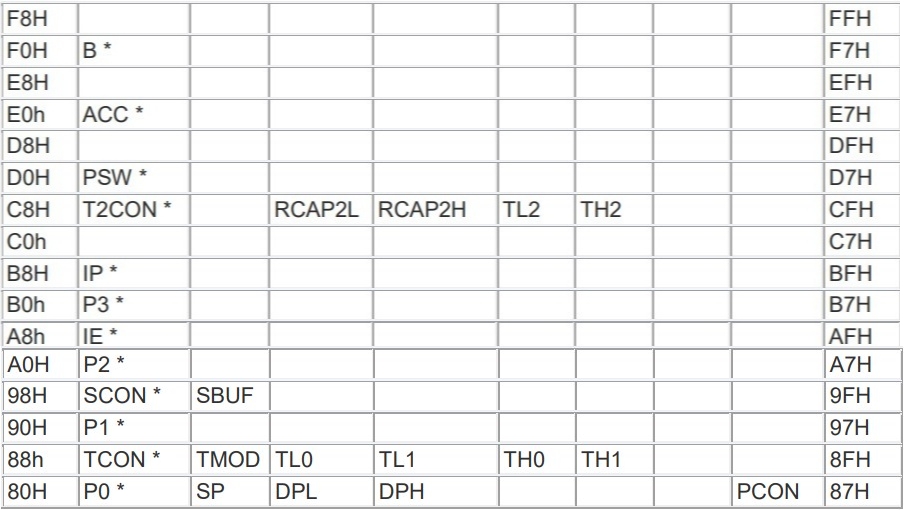
sbit 是 8051 擴展的變數類型,非標準 C 語法,移植的時候需要將其修改成標準 C 操作語法,另外在 AndesCore™中,所有的暫存器都是單獨存在的,不會佔用記憶體的空間。
2.7. 指標使用差異
8051 中兩種類型的指標,分別是記憶體指標和通用指標,通用指標由 3 個位元組組成,第一個位元組用來指明對應的記憶體類型,所以這種類型的指標類型佔用空間更大也更慢,記憶體指標只能用來訪問指定類型的記憶體空間。

而在 AndesCore™上指標不會有這方面的限制,它是一個 32bit 的資料,普通的暫存器就可以存放指標內容,可以訪問到系統 4G 範圍內的空間(N705,N801 位址空間只有 16M,N968A 以上的 CPU 位址空間可達 4G)。
2.8. 函式宣告差異
在 8051 中由於堆疊空間有限,如果有函數是可重入的,需要在函式宣告的時候用關鍵字 reentrant 做說明。8051 的中斷處理函數則需要使用關鍵字interrupt 聲明,中斷處理函數有時也需要用 using 關鍵字指明哪一暫存器組會被使用到。
在 AndesCore™中,都採用標準的 C 語法,在聲明函數時並不需要這些附加的聲明。AndesCore™遵行底層的 ABI 機制,編譯器處理底層的暫存器及堆疊相關機制。對於上層用戶來說是透明的。
3. 系統相關事項說明
3.1. 操作模式
8051 只有一種 mode,AndesCore™有兩種 mode,分別是 superuser mode 和 user mode,當系統上電啟動時是在 superuser mode,或者當系統進入到中斷或者異常時也進入到 superuser mode,當從中斷或者是異常返回後,會返回到 user mode。由於 8051 沒有mode 切換的問題,所以在移植的時候只需要理解 AndesCore™在 mode 方面的機制就可以。
3.2. 系統的啟動
8051 和AndesCore™的系統啟動過程類似,通常在 0 位址存放中斷向量表, 第一個向量表是 reset,當系統上電或者是 reset 後,經過該向量會跳轉到一個啟動函數中,該啟動函數會完成系統啟動所必要的步驟,比如設置 CPU,初始化 SoC,清理記憶體,初始化 C 運行環境等, 最後完成所有的準備後跳轉到 main 函數。
3.3. 中斷處理
8051 有 5 個中斷源,通常中斷向量表只是一個跳轉,會跳到真正的中斷處理函數,8051 只能設置成兩級的中斷優先順序。

AndesCore™包含了 9 個內部異常,中斷向量號對應於從 0 到 8, 9 之後對應於外部中斷,在 Internal Vector Interrupt Controller (IVIC)mode 時可支援 32 個外部中斷,
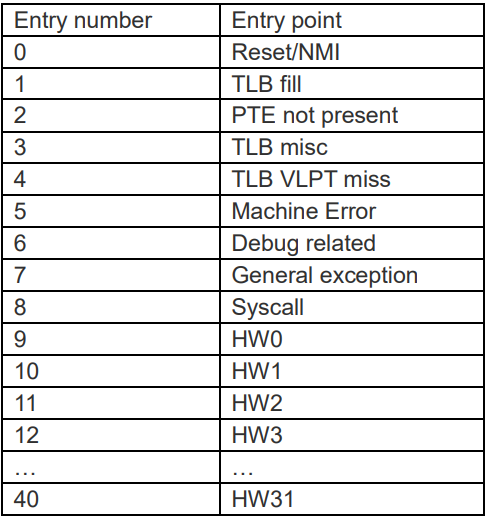
當 External Vector Interrupt Controller(EVIC) mode 時由外部中斷控制器決定,最多有 64 個。
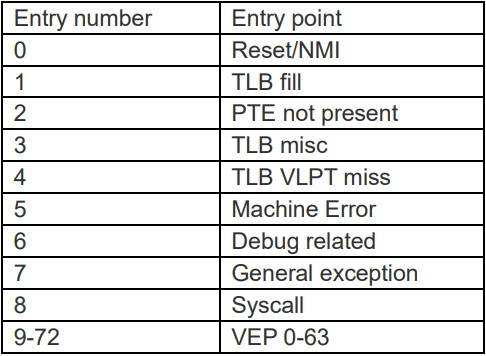
中斷的處理由以下幾部分組成:
1. 實現中斷處理函數
可以用組合語言實現 8051 的中斷處理函數,也可以用 C 來實現,在 8051 中 C 實現的中斷處理函數會有一個”interrupt”的關鍵字,如果有暫存器 bank 被使用到,還要加上”using”關鍵字。如果要將中斷處理函數固定在特定位置還需要使用”at”關鍵字,而 AndesCore™使用的是標準的 C 語法,不需要為中斷處理函數做這些設置。
2. 中斷向量表的產生
8051 中斷向量表擺放在 0 開始的位置,在 AndesCore™中硬體可以設定啟動位址,通常設為 0 位址,也可以是非 0 位址,中斷向量表存放在對應系統啟動位址處。在程式編寫過程中可以通過標準的 gnu 語法再加上 link script 的 SaG 工具,以使產生的中斷向量表在連結的時候存放於特定的位置。
3. 中斷配置
在 8051 中,需要做以下設置
1. IE 暫存器中 Individual Interrupt Enable 位設 1
2. IE 暫存器中 EA(Enable All)位設 1
3. 當是外部中斷時,配置相關的 pin 為輸入,並設置對應的觸發屬性為edge 或 level 觸發。
而在 AndesCore™中需要做以下設置:
1.設置 CPU IVIC 或者 EVIC mode
2.設置 INT_MASK 位
3. 設置中斷的優先順序
4. 關於異常處理差異
在8051 中沒有異常處理向量,所以在8051 中並沒有這部分的處理函數, 在 AndesCore™中有一些系統的異常處理向量,比如 Machine Error, General Exception, 建議在 AndesCore™上實現對應的處理函數,當發生這類異常時做一些基本的處理。
3.4. 時序和延遲
在 8051 中可以採用 NOP 指令來延遲,在 AndesCore™中也有 NOP 指令來達到類似目的。
3.5. 電源管理
8051 單晶片中有兩種省電方式,分別是空閒方式和掉電模式,單晶片處於空閒工作方式時,CPU 處於睡眠狀態,它的晶片內其它部件還是會繼續工作,晶片內 RAM 的內容和所有專用暫存器的內容在空閒方式期間都被保存下來了, 可以通過中斷或者硬體重定來終止空閒工作方式。單晶片處於掉電工作方式時,晶片內的振盪器停止了工作,因此它的一切都被迫停止了。但晶片內 RAM 的內容和專用暫存器的內容一直保持到掉電方式結束為止。掉電方式的喚醒方式只有一種,就是硬體重定。
在AndesCore™上,可以通過軟體 standby 指令使 CPU 進入到低功耗模式, 通常標準 c 代碼並不能直接控制硬體,Andes 的 compiler 提供了 intrinsic 函數來做到這點。分別是: nds32_standby_no_wake_grant(),
nds32_standby_wake_grant(), nds32_standby_wait_done().指定系統進 入低功耗模式時被喚醒的方式,分別是外部中斷的中斷喚醒,電源管理模組喚醒, 和中斷配合電源管理模組喚醒,可以根據系統需要分別設計。
4. 從 8051 移植到 AndesCore™ 上注意事項
從一個 8051 工程,當移植到 AndesCore™上時有以下注意事項:
1.記憶體映射,代碼和資料擺放位置相關的設置。
2. 可以不必考慮變數數目,或者是函數的 overlay, 因為在 32bit 的AndesCore™上開發時記憶體空間通常不會像 8051 那樣小。
3. 如果空間允許,在 AndesCore™上儘量使用 32bit 的資料類型,這樣效率會更高。
4. 在 8051 上用於表示記憶體區域屬性的標誌如(idata, xdata, bdata, pdata等)在 AndesCore™上可以移除。
5. 在 8051 上不需要設置記憶體區塊模式,比如:small, compact, large 等。
6. 在 8051 上用於表示對象遠近的屬性”near” 和”far”, 都可以移除,AndesCore™上的指標的訪問可以達到所有位址空間。
7. 在中斷處理函數中不需要像 8051 那樣指定哪塊暫存器塊會被用到的關鍵字”using”。
8. 在 8051 上中斷處理函數就和普通的函數一樣,不需要設置其它的關鍵字, 如 interrupt。
9. 如果有 8051 組合語言部分移植到 AndesCore™,需要重新實現,盡可能的用 c 來實現,便於維護和調試。
10. 在 8051 中使用到的#progma 相關部分需要刪除。
11. 在 AndesCore™中函數不需要聲明為”reentrant”屬性。
12. 如果使用了數學運算,在 8051 中默認是使用 32bit 單精確度浮點,如果要保持和 8051 中相同的精度,需要將函數名做一些調整,如將 sin()改成sinf()。
5. 中斷向量及異常處理函數例子
以中斷向量及中斷處理函數的例子說明差異及移植。
5.1. 組合語言實現中斷向量表
[8051]
該例子顯示怎樣用組合語言設置 8051 的中斷向量和中斷處理函數,在 8051 組合語言中 ORG 指定了後面組合語言代碼的位置,後面的中斷向量通常是一個跳躍陳述式。如下例第一個向量跳到主函數 MAIN 函數中,另外一個外部中斷1,也是一個跳轉指令:LJMP INT 到後面的用組合語言實現的中斷處理函數 INT 中。
[AndesCore™]
該例子顯示怎樣用組合語言設置AndesCore™的中斷向量表和中斷處理函數, 該例子中 exception_vector 是中斷向量表的 label, 後面分別表示第 0,1,2,3…個中斷向量,它們只是簡單的跳轉指令,跳到具體的執行實體中去,如 vector 0 跳到_start,做系統相關的初始化操作,_start 是系統啟動代碼,用組合語言來實現。vector 9 後面對應的是外部中斷,中斷處理函數如 OS_Trap_Interrupt_HW0, OS_Trap_Interrupt_HW1… 它通常用 C 來實現,可以參考後面 5.2 章節的AndesCore™中斷處理函數範例。

在上面用組合語言設置 AndesCore™的中斷向量表的例子中,我們需要將中斷向量表最終設定在 0 位址處,可以通過 section 語法配合 SaG 工具實現,例子中我們設定該段的 section 名為.vector, 所以在 SaG 中,我們自訂一個USER_SECTION 為.vector,並將.vector 放在 0 開始的地方並作為第一個section。
通過上面的 SaG 語法,並使用 Andes 提供的 SaG 轉 ld 的工具,可以產生類
似以下的 ld,在工程進行連結的時候選擇該 ld 時就能確保 .vector 連結的位址位於 0 處。
5.2. 中斷處理函數的 C 實現
[8051]
怎樣用 C 寫 8051 的中斷處理函數範例

[AndesCore™]
怎樣用 C 寫 AndesCore™的中斷處理函數範例 
6. 適用於 MCU 的 Andes CPUs
Andes 有三款非常適用于 MCU 應用的 CPU,分別是:N705,N801,N968A,如下圖所列:
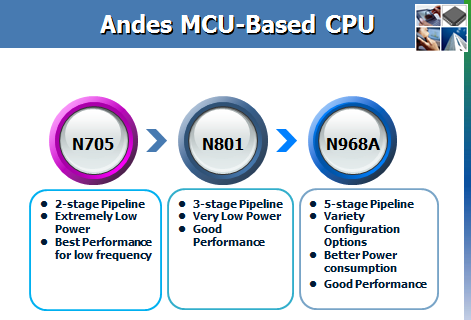
N705 和 N801 分別採用了兩級和三級流水線,都具有很低的功耗和很好的性能,當應用需要的頻率較低時,使用兩級流水線的 N705 能發揮出更好的性能和更低功耗的特性,相比於 8051,兩級流水線的 N705 在頻率方面高出許多,比如在 TSMC 40nm LP 工藝下能跑到超過 240MHz,所以完全能勝任 8051 的應用需求。N968A 使用了五級的流水線,同樣有低功耗的特性和很好的性能,同時該款 CPU 具有很強的可配置性,如支援多種匯流排界面,還支持了專門為audio 的加速指令,N968A 是一個性能好,功耗低,又具備強大的可配置特性, 適合於多種應用。
7. 總結
AndesCore™使用標準的 C 語法開發,方便快捷,同時作為 32 位元 RISC(精簡指令集)架構的 CPU,AndesCore™有多款適用于 MCU 應用的 CPU,相對於8051 具有功耗,性能方面優勢。
中斷處理固定優先權與可程式化優先權的差異性
王勝雯,經理,晶心科技股份有限公司
在現今 SOC 設計中,當周邊裝置(Periphral IP)想要和中央處理器(CPU)溝通時,最常使用的機制則是透過中斷(Interrupt)。由周邊裝置觸發中斷給中央處理器,當中央處理器接收到中斷後,則可判斷是由哪個周邊裝置觸發些中斷,接著處理相對應的中斷處理程式(ISR,Interrupt Service Routine),藉此達到彼此溝通的目的。但在同時間若有多個周邊裝置同時觸發中斷給中央處理器時,優先處理程序就成為了非常重要的一環。
Andes Core™在中斷優先權處理方面,共支援兩種模式:固定中斷優先權(Fixed Priority)和可程式化中斷優先權(Programmable Priority)。當配置在固定中斷優先權時,中斷處理優先權會依照中斷輸入腳位的順序來決定優先處理權,腳位數字越小其優先權越高(Low Interrupt Input Number High Priority),而配置在可程式化中斷優先權時,可將所有中斷輸入設置成四個層級的優先處理權,中央處理器在同時發生觸發中斷時會依照其設置的層級來決定優先處理權,若發生層級相同時則再以中斷輸入腳位的順序來決定優先處理權。
而在中央處理器進入中斷處理程序後,倘若希望能讓其他優先權較高的中斷觸發中央處理器進而處理該中斷處理程序,在軟體部分又應該怎麼設置來達到巢狀中斷的結構,我們將在本文介紹給使用者參考,期望能對使用者有所助益,也希望讀者不吝指教提供您寶貴的意見。
1. 中斷優先權介紹
AndesCore™共支援兩種中斷優先權處理模式:固定優先權模式(Fixed Priority)與可程式化優先權模式(Programmable Priority)。以下的介紹將架構於AndesCore™ N801-S 這顆中央處理器。帶領使用者循序漸進地,了解這兩種中斷優先權處理模式的差異。
1.1. Definition
AndesCore™ N801-S支援兩種中斷優先權模式,在硬體配置時就需要先決定中斷優先權的模式,如圖1的硬體配置視窗所示,首先,我們先介紹關於這兩種模式的定義。

圖1. 硬體配置視窗
1.1.1 Fixed Priority Mode
在AndesCore™ N801-S硬體配置時,若配置在中斷固定優先權模式下,中央處理器在多個觸發中斷同時發生時,則依照中斷輸入腳位來決定處理順序,請參考表1。
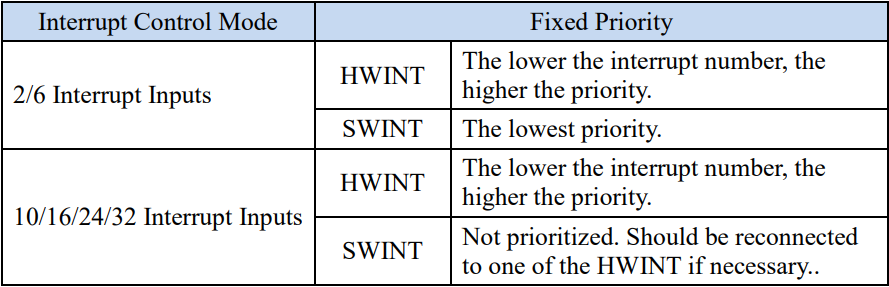
表1. Fixed Priority Mode 觸發中斷處理優先順序
1.1.2 Programmable Priority Mode
在AndesCore™ N801-S硬體配置時,若配置在中斷可程式化優先權模式下, 中央處理器在多個觸發中斷同時發生時,則依照每個中斷輸入設置的優先層級來決定處理順序,請參考表2。而在可程式化優先權模式下,每個中斷輸入都有四個優先層級可以讓使用者自行設置,使用者也可以透過系統暫存器(PPL2FIX_EN) 將模式從可程式化優先權模式切換至固定優先權模式。
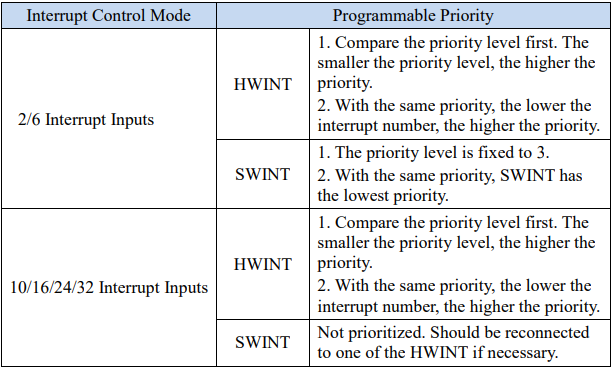
表2. Fixed Priority Mode 觸發中斷處理優先順序
1.2. System Register
關於上述兩種中斷優先權模式,在可程式化優先權模式下使用者可透過設置AndesCore™ N801-S 內部的 system register 來設置每個中斷優先權層級,以及將可程式化優先權模式切換回固定優先權模式。
設置優先權的system register為INT_PRI(ir18)與INT_PRI2(ir28),每個中斷輸入都有四個層級讓使用者規劃,其格式如圖2與圖3的暫存器配置,而設定值的優先權可參考表3的解釋。


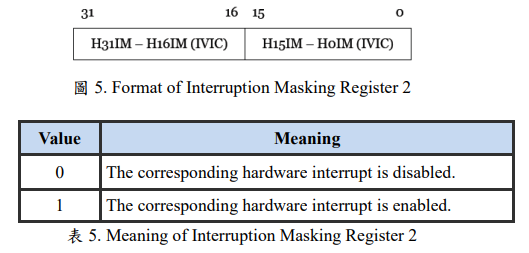
在硬體配置成可程式化優先權模式下時,有一個system register 為INT_CTRL(ir19)。透過設置INT_CTRL.0,使用者在硬體配置成可程式換優先權模式下切換回固定優先權模式。其格式如圖4的暫存器配置,而內容值的意義可參考表4的解釋。當PPL2FIX_EN=1時,CPU處理中斷的方式則會與硬體配置成固定優先權模式的情況一樣,CPU只根據中斷輸入的號碼大小來決定處理順序。

另一個控制中斷輸入 on/off 的 system register 為 INT_MASK2(ir26),使用者可以透過設定該暫存器來決定各中斷輸入是否開啟。
2. 中斷優先權處理程序介紹
在介紹完中斷處理模式相關定義之後,本章節提供在實際整合與應用上的
範例,讓使用者可更了解在不同中斷處理模式下的差異。
2.1. Multi-Interrupt at Fixed Priority Mode
本章節介紹當硬體配置在固定中斷優先權模式下時,發生多個中斷時,CPU 在處理的程序。
圖 6 中,表示同時發生 HW_INT1、HW_INT28 與 HW_INT30 三個中斷源, 此時CPU 會依照中斷輸入號碼大小(號碼越小優先權越高)來決定處理優先順序, 所以 CPU 依序先處理 HW_INT1,然後再接著處理 HW_INT28,最後再處理HW_INT30。
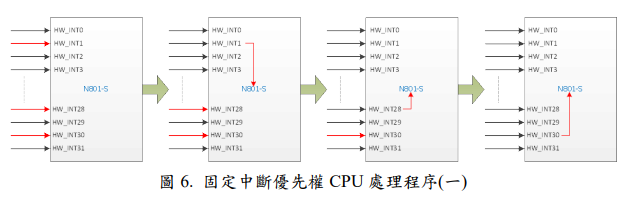
圖 7 中,表示同時發生 HW_INT1 與 HW_INT30 兩個中斷源,在 CPU 處理完 HW_INT1 後應該接著處理 HW_INT30,但在處理 HW_INT1 的同時,外部中斷源又接著發生 HW_INT28,所以在 CPU 在處理完 HW_INT1 後會優先處理HW_INT28,然後最後才處理 HW_INT30。
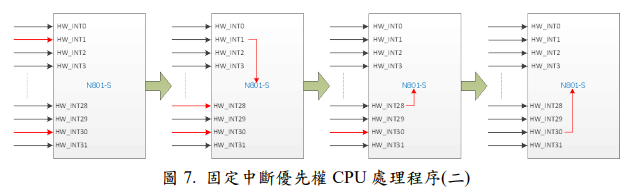
圖 8 中,表示同時發生 HW_INT28 與 HW_INT30 兩個中斷源,在 CPU 處理完 HW_INT28 後接著處理 HW_INT30,此時外部發生了 HW_INT1,在沒有使用巢狀中斷的情況下,此時 CPU 已經在處理 HW_INT30,所以並不會因為HW_INT1 的中斷優先權大於 HW_INT30 而去處理 HW_INT1 ,必須等到HW_INT30 處理完畢,最後才處理 HW_INT1。
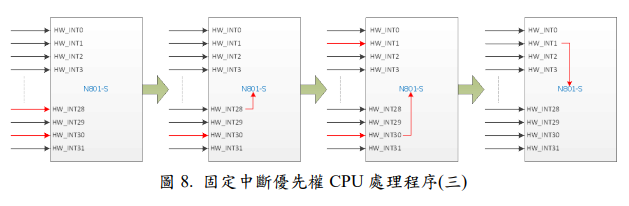
2.2. Multi-Interrupt at Programmable Priority Mode
本章節介紹當硬體配置在可程式化中斷優先權模式下時,發生多個中斷時,CPU 在處理的程序。
圖 9 中 , 表 示 同 時 發 生 HW_INT1(PPL=2) 、 HW_INT28(PPL=0) 與HW_INT30(PPL=1)三個中斷源,此時 CPU 會依照中斷優先權大小(PPL 值越小優先權越高)來決定處理優先順序,所以 CPU 依序先處理 HW_INT28(PPL=0),然後再接著處理 HW_INT30(PPL=1),最後再處理 HW_INT1(PPL=2)。
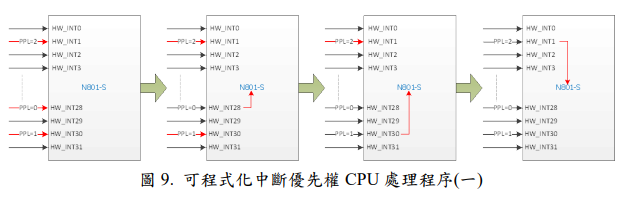
圖 10 中, 表示同時發生 HW_INT1(PPL=1) 、 HW_INT28(PPL=0) 與HW_INT30(PPL=1)三個中斷源,此時 CPU 會依照中斷優先權大小來決定處理優先順序,而發生中斷優先權大小相同時,則再依照中斷號碼大小(號碼越小優先權越高) 來決定處理優先順序。CPU 依序先處理 HW_INT28(PPL=0),此時HW_INT1(PPL=1)與 HW_INT30(PPL=1)的 PPL 相同,CPU 則依照中斷輸入號碼大小來決定優先順序,所以先接著處理 HW_INT1(PPL=1) ,最後再處理HW_INT30(PPL=1)。
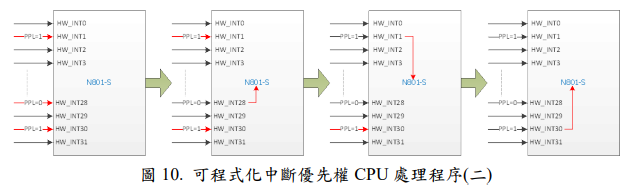
圖 11 中,表示同時發生 HW_INT28(PPL=0)與 HW_INT30(PPL=1)兩個中斷源,此時 CPU 會依照中斷優先權大小來決定處理優先順序,所以 CPU 先處理HW_INT28(PPL=0),但在處理 HW_INT28(PPL=0)的同時,外部中斷源又接著發生 HW_INT1(PPL=0),所以 CPU 在處理完 HW_INT28(PPL=0)後會優先處理HW_INT1(PPL=0),最後再處理 HW_INT30(PPL=1)。
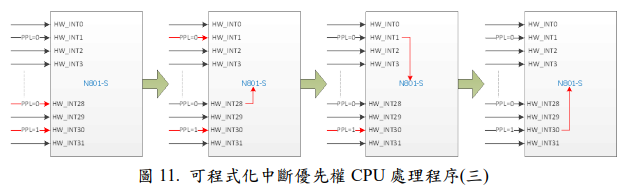
圖 12 中,表示同時發生 HW_INT28(PPL=1)與 HW_INT30(PPL=2)兩個中斷源,此時 CPU 會依照中斷優先權大小來決定處理優先順序,所以 CPU 先處理HW_INT28(PPL=1) , 然 後 接 著 處 理 HW_INT30(PPL=2) , 但 在 處 理HW_INT30(PPL=2)的同時,外部中斷源又接著發生 HW_INT1(PPL=0),在沒有使用巢狀中斷的情況下,此時 CPU 已經在處理 HW_INT30(PPL=2),所以 CPU 並不會因為 HW_INT1(PPL=0) 的優先權大於 HW_INT30(PPL=2) 而去處理HW_INT1(PPL=0) , 必須等到 HW_INT30(PPL=2) 處理完畢, 最後才處理HW_INT1(PPL=0)。
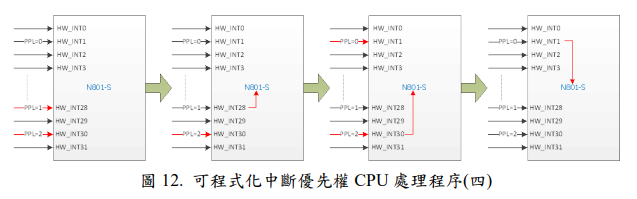
3. 結語
透過上述的幾種多個中斷源發生時,N801-S 在處理程序上的方式,相信各位對於固定與可程式化中斷優先權的使用有了更進一步的了解,對於在中斷源的配置上就能依照電路需要來規劃輸入腳位以及靈活運用可程式化優先權中斷的功能。
在 AndesCore™所提供的兩種中斷優先權模式裡,CPU 在進入中斷處理程序後,硬體會自動將 GIE(Global Interrupt Enable)關閉,讓 CPU 能專注於處理當前的中斷程序,然後在處理完畢中斷程序後硬體再自動將 GIE 開啟,但是如果使用者希望能夠在中斷處理程序過程中又允許優先權更高的中斷源能夠介入,並且讓 CPU 能夠暫停當前的程序,進而優先處理該更高優先權的中斷,AndesCore™ 也支援這樣的巢狀中斷(Nested Interrupt)處理模式,而那又是另一個課題了,我們將在之後的技術文章中再針對AndesCore™巢狀中斷的程式處理方式有更詳細的應用方式與介紹。
Andes SAG 應用實例
在嵌入式開發中,系統軟體設計特別是各種記憶體的規劃是必不可少的一個環節,它也直接體現在連結腳本的撰寫上。因連結腳本的語法相對複雜和篇幅較大,前期撰寫和後期維護對工程師來講難度都很大, 但對使用 AndesCore 做開發的工程師來講,Andes SAG 是一大福音,它提供簡單直觀的描述語言替代了複雜的 linker script。我們收到的回饋也證明,越來越多的工程師開始採用 Andes SAG 替代 linker script,之前我們有一篇技術文章對 SAG 的語法格式做了介紹並說明如何使用,本文將展示四個實際專案開發的例子,以幫助廣大開發者更好的熟悉和理解 Andes SAG,同時可以作為開發時的參考。
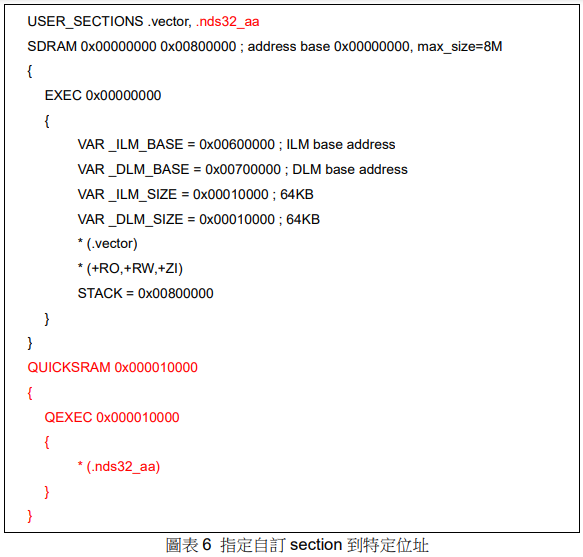
1. 將函數和變數指定到特定位址
第一個例子是如何將函數和變數的位址指定到一個特定的位址上。有這樣要求的原因有很多,諸如 SOC 的執行位址空間不連續,或者需要高效使用某一塊效率很高的記憶體等情況。解法分為兩步:一,在 SAG 檔中添加自訂的 section, 將此 section 的 VMA 設定到指定地址;二,在 C 語言中,將需要改變的函數和變數用特定的語法放在自訂的 section。
圖表 1 是在SAG 中自訂section 的例子。第 1 行關鍵字 USER_SECTIONS 表示後面接的這幾個 sections 都是由使用者自訂的 sections。

圖表 1 中,第 4 行至 8 行表示從 0x0 開始的區域是唯讀區,包含程式碼(.text section)及唯讀資料段(.rodata section)。第 9 行,MYRAM0 部分表示.mysection0 的 VMA 從 0x00014000 開始。以此類推,MYRAM1 和 MYRAM2 部分各自表示mysection1 和.mysection2 的 VMA 起始位置,因為 LMA 與 VMA 不一致,所以需要做 copy LMA 位址至 VMA 位址的工作。第 21 行的 RAM1 裡放的是.data 及.bss sections,執行時期會從 0x00010000 開始,原始程式碼中須做到將 data 從LMA 位址複製至 VMA 位址,可以使用,可以使用 __data_lmastart 與 __data_start 來定址。
指定函數放在自訂 section 裡,在原始程式碼的對應處要使用 attribute ((section(“.mysection0”)))語法,完整寫法請參考圖表 2a。圖表 2b是另外一種寫法。


指定全域變數 gdata1 放在自訂 section .mysection1 裡,在原始程式碼的對應處要使用 attribute ((section(“.mysection1”)))語法,完整語法請參考圖表3。

將函數和變數這樣指定後,編譯後的 elf 執行檔可以清晰看到對應 Section 的 LMA 與 VMA 如圖表 4.

2. 實現 IVB 在執行時切換
有一個客戶需要系統在開機與正常執行時能有不同的 ISR,即是同一個中斷的服務函數在開機和正常執行時會不一樣。對於這個問題的解法有很多,我們今天介紹是其中一種解決方法:設置一個新的 Vector Table,新的 Vector Table 會跳到新的 ISR;通過 SAG 將新的 Vector Table 指定到一個特定位址上;當程式開機完成,需要正常執行時,只需要去修改 IVBASE (ir3)這個寄存器。
所以完成這個例子的重點是如何在組合語言程式碼中建一個新的 vector table 並指定到自訂的 section 中。表5是實例的寫法:

圖表 5 重點是是第一行,.section 是用來定義非標準的 section,.nds32_aa 即為非標準 section 的名稱,”a”表示 allocable, “x”表示 executable. 因為 Andes 的標準 vector table 一般會放在.nds32_init section,所以新的 vector table放.nds32_aa 裡,名稱不一樣能區別就好。接下來是讓新的自訂 section .nds32_aa 執行在特定位址上,如圖表 6 所示。
這樣新的 vector table 的首位址會被固定到 0x10000 的位置,當程式開機完成,只需要將 IVBASE 設定到這個位址,那麼當有中斷進來,就會跳到新的 Vector Table 中。
3. 指定一個或幾個 C 檔的所有 section 到指定位址
上兩個例子有共同點是通過程式設計將某一段程式放到自訂 section,區別在於一個是指定 C 語言函數和變數到自訂 section,一個指定組合語言函數到指定的 section,都需要改動原始程式碼。然而對於一些應用場景,比如不提供原始程式碼只有編譯好的.o 或者.a 檔,如果想將.o 檔裡的 section 指定到特定位址執行,這個時候該如何做呢?請參考圖表 7A 的寫法,這表示我們要將 hello.o 的唯讀區,包含程式碼(.text section)及唯讀資料段(.rodata section)放在 LMA 及VMA 在 0x10000 的地址上。

在整個 project 中如果將每個.o 檔都列出來,那麼整個 SAG 文檔將變得難以閱讀,而且在給後期維護帶來麻煩,這種解法不好。如果使用者只需要排除幾個.o 檔,對於熟悉 GNU linker 的讀者會想到“EXCLUDE_FILE”這一語法,讓使用者可以很方便地在 Linker script 中實現這一需求。Andes SAG 也與時俱進地引入這一語法。圖表 7B 正是這樣一個例子,它將 uart.o 中所有的 section 都放到一個特定位址去執行,因為 LMA 與 VMA 不一致,所以需要將 LMA 位址上的程式碼複製到 VMA 位址,而其它的保持不變,且可正常執行。

圖表 7B 支援“EXCULDE_FILE”
4. 如何避免 LMA 或 VMA 的偏差
在前三個例子中,都是舉例去說明如何實現將程式的某一部分的 LMA 或者 VMA 固定在某一個特定位址上,這是對 linker script 的基本要求。嵌入式軟體工程師需要知道,當某一 section 的 LMA 與VMA 不相等時,那麼在程式初始化時需要將這一 section 從LMA 的位址複製到 VMA 的位址。初始化做複製時,這些 section 的LMA 和VMA 都是在 linker script 中給定值的,代碼中只是去做引用。 Andes SAG 同樣可以給變數 LMA 和 VMA 給予定值,但如何定值呢,是不是一個一個緊湊地排列下來?答案很顯然是不。很多工程師都知道,資料存放有Alignment 的要求,比如 4 Byte 的Word 其存放的首位址需要是 4 Byte Align; 程式呢,因為最佳化的需要,比如在 Andes 編譯器在-O3 等級下,函數的首位址同樣強制 4 Byte Align。既然有對齊的要求,就必然有 gap 存在,當然這裡舉出的對齊因素只是讓讀者瞭解到連結器對某一 section 的LMA 或VMA 的數值確定不只是單純累加,Andes SAG 能自動處理好大部分對齊狀況。但在一些較複雜的例子中,需要給 Andes SAG 更多指示,讓它工作正確。
首先,我們來看圖表 7 所舉出的例子,這一行“LOADADDR NEXT__uart_lmastart”,有一個關鍵字“NEXT”。它的作用就是讓 SAG 知道,這個變數的取值是下一個 Section 的開始,而不是上一個 Section 的結束。為了讓讀者更明白所表示的含義,我們首先來看依照圖表 7 的 SAG 編譯出的 elf 執行檔 header 資訊,如圖表 8:

可以看到.text_*uart.o 的 LMA 應該是 0x1c60, 上一個 section(.bss)的LMA 結束地址應為:0x1c48+0x10=0x1c58,所以為了清晰地讓 SAG 知道 uart_lmastart 代表.text_*uart.o 的LMA 開始而不是.bss 的 LMA 結束,我們應該用 NEXT 去修飾它。
然後,我們再來看圖表 9 的例子,這個例子中,使用“LMA_FORCE_ALIGN 的原因是因為可能某一個 section 的 size 只有 2 Byte(不是 4 Byte 的整數倍),但下一個 section 的 VMA 起始位址需要 4 Byte Align,這時就會出現衝突,為解決衝突,Andes SAG 引入這一關鍵字“LMA_FORCE_ALIGN”,強制讓 LMA 與 VMA 用同一個值去做 Align。


我們用圖表 9 的 SAG 例子去編譯對應的 project,可以看到圖表 10 中 section .sbss_b 的 LMA 已經被從 0x1d42 調整到 0x1d44。

5. 結語
Andes 提供簡單易用的 SAG 工具幫助工程師替代了複雜的 linker script,可以大大提高在 Andes core 平臺上的軟體發展效率。本文從實際例子出發,介紹了 Andes SAG 工具如何快速解決工程實際問題,說明了 Andes SAG 強大而且容易上手。然而工具的功能越強大,也就需要工程師多加深入瞭解功能設計的緣由,這也正是最後一個例子展現出來的道理,即是透徹瞭解就可以熟能生巧。希望廣大讀者能熟練掌握 Andes SAG 這樣一把利器,在軟體發展中發揮四兩撥千斤的作用。
參考文檔:
1: BSP321 programming guide link generator
2: The GNU Linker Manual
快速產生linker script 的Andes SAG 機制
在嵌入式系統設計中,通常使用不同的記憶體,如 Flash、SRAM、SDRAM, 並位於不同的物理位址空間,怎樣更好地利用這些不同的記憶體並讓系統高效率地執行呢?通常這需要複雜的 linker script 來管理實作,而 Andes 提供了 SAG 語法(Scattering-And-Gathering),SAG 能夠將載入和執行時記憶體中的代碼和資料描述在一個SAG 格式的文字描述檔中,並通過linker script generator tool 將SAG 檔轉化為標準 GNU 的 linker script 檔,以供 link 程式時使用。採用 Andes SAG 機制,不僅可以幫助工程師清晰的描述記憶體的使用情況,更可以避免使用複雜的標準 linker script 語言 。本文詳細介紹了 SAG 語法格式,並以實際專案為例, 闡述 SAG 的使用方法和益處。
1. Andes ELF 檔案的結構
Andes 使用標準的 GNU link script 格式,Andes 的可執行檔案也遵行標準的ELF(Executable and Linking Format)格式。
ELF 檔案主要由 .text 段 .data 段 .bss 段,還有一些其它的段如:.debug .comment 段組成。
下面以一個簡單的 linker script 的例子作為說明:

SECTIONS 是 linker script 語法中的關鍵 command,它用來描述輸出檔的記憶體佈局。例如上例中就含.text, .data, .bss 三個部分。
.=0x10000; 其中的”.”是定位點(location counter -LC)。表示.text 段虛擬位址(VMA)從 0x10000 開始的。
AT 用來說明載入位址,AT(0)表示.text 段的載入地址是 0。{ *(.text) },這個表示輸出檔的.text 段內容由所有輸入檔()的.text 段組成。後面的一個. = 0x40000。如果沒有這個設定值,那麼 LC 應該等於 0x10000+sizeof(.text),這裡強制指定 LC=0x40000。表示後面的.data 段的虛擬位址(VMA)從 0x40000 開始。
LOADADDR 用來得到載入地址,此處.data 段的載入地址是 AT(LOADADDR (.text) + SIZEOF (.text)),它緊接著.text 段,.data 為所有輸入目的檔案的.data段構成。同理,.bss 段的虛擬位址是緊接著.data 段虛擬位址之後,而載入位址是緊接著.data 段載入位址之後的。.bss 段由所有輸入目的檔案的.bss 段組成。
通常在實際使用中的 linker script 會更加的複雜,SAG 機制能夠很好的簡化linker script 的設計,那接下來將對 SAG 機制做介紹。
2. Andes SAG 語法
SAG 語法的 BNF 符號表示法如下表:
SAG 格式總覽“
SAG 語法格式由:load regions、execution regions 和 input sections 等組成, 如下圖所示: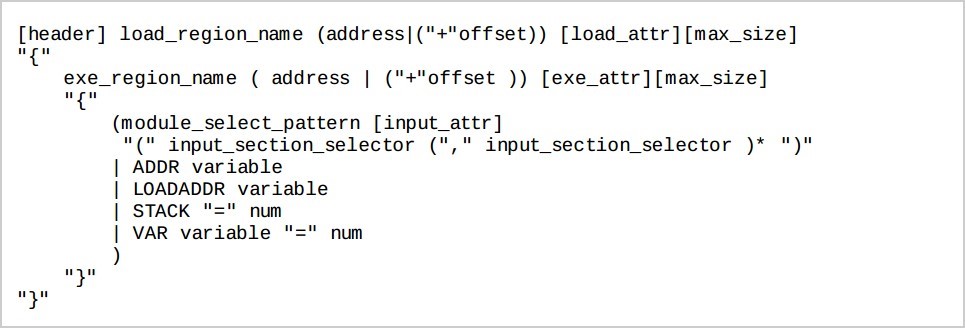
2.1 關 於 LMA 和 VMA
一般在嵌入式系統中,程式載入和執行在不同的位址空間,LMA 表示的是程式載入位址,VMA 表示的是程式執行位址,當 LMA 不等於 VMA 時,程式在載入後不能直接執行,而程式執行前,要把程式的內容複製到對應的記憶體位址處, 才能正確地執行。
2.2 header 格式  當要使用者自訂的 section 時,必需在 USER_SECTIONS 中定義。
當要使用者自訂的 section 時,必需在 USER_SECTIONS 中定義。
2.3 Load Region(載入區)
Load Region 格式為: load_region_name 表示某個程式載入區的名稱。
load_region_name 表示某個程式載入區的名稱。
address 表示的是 LMA。
offset 表示的是偏移量,當此時是第一個 load region 時表示的是與 0 位址的偏移量,當表示的不是第一個 load region 時,表示的是與前一個 load region 結尾處的偏移量。
load_attr 表示屬性,現在可以設置為 ALIGN alignment, 如 ALIGN 0x4。
max_size 表示該載入區域的最大值。
例子:
LOAD_ROM_1 0x0000 ALIGN 0x4 0x10000
在這個例子中 load_region_name 是:LOAD_ROM_1,LMA 是 0x0000,以4-byte 對齊,max_size 是 64K byte
2.4 Execution Region(執行區)
Execution Region 格式為:  exe_region_name 用於表示某個程式執行區的名稱
exe_region_name 用於表示某個程式執行區的名稱
address 表示的是 VMA。
offset 當表示的是第一個 execution region,表示的是與該載入區的偏移量, 當表示的不是第一個 execution region 時,offset 表示的是前一個 execution region 結尾處的偏移量。
exe_attr 表示屬性,如可以設置為 ALIGN alignment,如 ALIGN 0x4。
max_size 表示該 execution region 的最大值。
例子:
EXEC_ROM_1 0x0000 ALIGN 0x4 0x8000
在這個例子中exe_region_name 是 EXEC_ROM_1,它的 VMA 是 0x0000, 以4-byte 對齊,max_size 是 32K byte。
2.5 Input Section(輸入段)
Input Section 的描述格式為: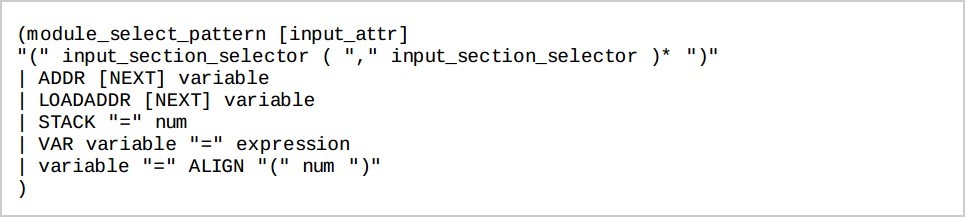 此處:
此處:
module_select_pattern 可以是目的檔案名。
input_attr 可以加上”KEEP”,其屬性可以保證該 section 在連結時不會被 remove 掉,或者是 SORT,用於排序。
例如:
program1.o KEEP (+RO)
此時該 input section 將包含目的檔案 program1.o 中所有的 read-only section,由於加了 KEEP,所以 prgram1.o 的 read-only section,在連結的時候不會被 gc-section 刪除掉。
input_section_selector 中最常用的是 input section_attr。
input section_attr 有以下幾種: input_section_selector 中另外一種用的是 input_section_pattern, 它的表示方法是 input_section_pattern ::= (.text | .data|…)。
input_section_selector 中另外一種用的是 input_section_pattern, 它的表示方法是 input_section_pattern ::= (.text | .data|…)。
ADDR variable 取得該處的 VMA 並存放在 variable 內。LOADADDR variable 取得該處的 LMA 並存放在 variable 內。STACK “=” num 為$sp 設定一個初始值 num。
VAR 用於設定並初始化一個變數。如 VAR _ILM_BASE = 0x00600000。
2.6 Execution Overlay Region(overlay 的執行區)
當使用 overlay 功能時,需要設定 Execution Overlay Region,設定格式為: 
它在後面加了個:OVERLAY 的關鍵字。
pagesize 後面表示 Overlay 的大小,當是 0 時,表示 software Overlay,其它的設置和前面的 execution region 相同。
2.7 Overlay Input Section(overlay 的輸入段)
當使用 overlay 功能時,要設置 Overlay Input Section,它和前面的 Input Section 類似。
3. 例子
如下例子所示的效果是:
在一個系統中,從 0x0000 開始,大小為 0x2000 的是 ROM1, 從 0x4000 開始,大小為 0x8000 的是 ROM2,此時我們需要將目的檔案 program1.o 的 RO 和 RW,ZI data。 存放在 ROM1 中,將其它目的檔案的 .text,RO,RW, ZI 存放在 ROM2 中。此時的 LMA 效果對應於下圖的左側。
同時需要將目的檔案program1.o 中的RW, ZI 的執行位址設置在從0x10000 開始的大小為 0x8000 的 DRAM 上,將其它目的檔案的 RW,ZI 的執行位址設置在從 0x18000 開始,大小為 0x8000 的SRAM 上。此時的 VMA 效果對應於下圖的右側。

該例子中 program1.o 中的 RO 和其它目的檔案中的.text, RO 的 LMA 和 VMA 是相等的,此時所有的 RW,ZI 的載入區域是分別在 ROM1 和 ROM2 上,但是執行位址是分別在 DRAM 和 SRAM 上,所以 RW,ZI 的 LMA 不等於 VMA, 所以在程式使用到 RW, ZI 所代表的.data,.bss 段之前需要將它們從載入區複製到執行區,以達到所圖中右側所示的效果。
對應的 SAG 可以這樣設計: 
利用 SAG 機制,除了快速設計上列所示的系統中儲存空間的分配,還可以快速的進行 overlay 程式的設計,overlay 程式主要是用於分時重複利用快速但儲存空間有限的記憶體。
4.將 SAG 檔轉換成 linker script
在 AndeSight™ 或者 BSP package 中提供了叫做 nds_ldsag 的工具,該工具可以將 SAG 檔轉換成標準的 GNU linker script 檔。在 cygwin 下,執行方法如下,filename.ld 就是我們希望獲得的linker script 檔。
./nds_ldsag.exe filename.sag -o filename.ld
5.結語
Andes 提供的簡單、易用的 SAG 描述語言,讓工程師根據系統中的存放裝置的特點,對程式的載入與執行區域進行很方便的設計和描述,甚至可以快速的進行更為複雜的 overlay 程式的設計,然後通過自動化工具 nds_ldsag 將 SAG 描述檔轉成標準 linker script 供 linker 使用,從而大大提高在 Andes core 平臺上的軟體發展效率。
參考文件:
1: Andes BSP v3.2.1 Programming Guide 第 14 章 ”Linker Script Generation”
2: The GNU Linker Manual
軟體 Overlay:程式編寫與除錯
賴歆雅,技術經理,晶心科技股份有限公司
近幾年來,SOC 為了支援更大的硬體資源,及更精確的演算法,很多應用中的韌體程式碼越來越大,但是售價卻要越來越便宜。各家廠商無不絞盡腦汁尋找降低成本的方法。
SRAM 在 SOC 上,是一個快速但單位面積較大的元件,而單位面積較大代表成本較昂貴。有一個降低成本的方法,是將程式碼放在較慢但單位面積較小的 flash 或 ROM 上,當系統需要執行裡面的某些程式碼時,才載入到記憶體裡執行。
如果用商店來比喻的話,有一個小店租在都市裡的黃金店面裡,小店的展示櫃很小,當客人想要看架上沒有的商品時,店員才從後面較大的倉庫裡,把商品拿出來放到展示櫃上。這裡的展示櫃就像 SRAM,昂貴但是有效率,倉庫就像 flash,便宜容積大但是存取較麻煩。
本文介紹的是軟體 overlay 的技術。除此之外,晶心科技也發展了硬體overlay 的技術,使得 overlay 執行更快,實作更為簡單。期望本文章能對使用者有所助益,也希望讀者不吝指教提供您寶貴的意見。
1. 軟體 Overlay 技術介紹及實作
我們拿一個情境實例做為說明,比方說程式碼的大小為 210KB,RAM 只有 64KB,我們把 RAM 規劃成一格一格的大小,比方說每 4KB 切成一塊。每 4KB 的大小可以在不同時間,更換成不同的程式碼,可以重覆利用 RAM 的空間。程式碼儲存在 ROM 或 flash 裡,只有在執行之前會將函式從 ROM 或 flash 裡動態載入 SRAM 裡。當這個函式執行完成,下一個函式要執行前,再載入下一個函式。
值得注意的是,每一格 SRAM 裡可載入的程式碼是互斥的,比方說有些不會同時使用的功能可以放在同一格裡,比方說 mp3 播放器,錄音和播放不會同時使用,就可以規劃重覆利用同一格 SRAM。
1.1 系統架構
請參考圖表 1,右邊長方形是 flash 的內容。0x0 起 1MB 的空間,flash 裡存放了程式碼和.data,及各個即將要被 overlay 的 sections。
圖表1的左邊長方形是SRAM規劃,位址從0x10000000開始,我們切出三格提供overlay的SRAM,分別是0x10800000, 0x10804000及0x10808000。Overlay 要規劃成幾格,或者每一格要切成多大塊,都是由使用者規劃。這裡的SRAM與flash的地址是以通用型Andes FPGA開發板作例子。讀者設計SOC時,可以根據實際需求訂定合理的位址。
程式執行時,0x10800000可以載入.ovly0或是.ovly1。0x10804000可以載入.ovly3或是.ovly2。0x10808000可以載入.ovly4或是.ovly5。
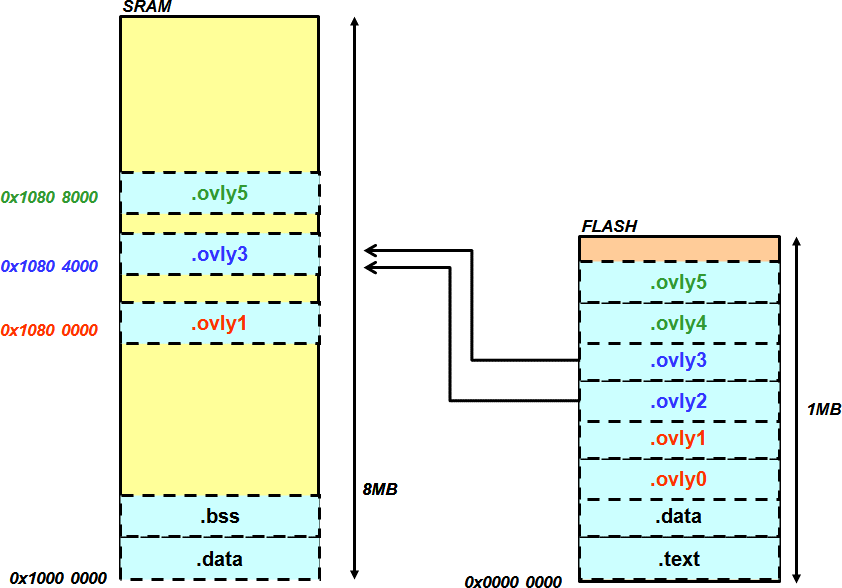
圖表1. 系統架構圖
1.2 overlay 的 sag 檔編寫
圖表 2 是範例 sag 檔。Sag 檔是 Andes linker script generator 所需要的輸入檔,執行linker script generator 後,輸出會產生GNU linker 需要的linker script。詳細語法說明可以參考 Andes BSP v3.2.0 User manual 第 12 章。
我們簡單介紹圖表 2 的語法。第 1 行關鍵字 USER_SECTIONS 表示後面接的這幾個 sections 都是由使用者自訂的 sections。在後面的章節,筆者會介紹如何把函式指定為這些自訂 sections。

圖表2中,第4行表示從0x0開始的區域是唯讀區,包含程式碼(.text section) 及唯讀資料段(.rodata section)。第9行,OVLY0從0x10800000開始,裡面有2 個sections可overlay,一個是.overlay0,另一個是.overlay1。以此類推,在OVLY1 和OVLY2都各有2個sections可以overlay。第24行的RAM1裡放的是.data及.bss sections,執行時期會從0x10000000開始。
1.3 sag 檔轉成 linker script
如圖表3,在cygwin下執行nds_ldsag軟體,將sw-ovly.sag轉成sw-nds32.ld檔。參數-o sw-nds32.ld為指定輸出檔的檔名。nds_ldsag軟體可以在AndeSight
2.0.1 MCU或是BSP v3.2.0裡取得。![]()
1.4 程式裡指定函式或變數放在自訂的 sections
GNU ld (linker)可連結目的檔為可執行檔,排列上的最小單位是section,基
本的sections為.text,.data及.bss這3個sections。為了達成分區overlay的功能, 必須指定函式或是變數在自訂的sections上。在前一節裡我們介紹了我們切出3 個區域可以做overlay,分別是OVLY0(從0x10800000起),OVLY1(從0x10804000起)及OVLY2(從0x10808000起)三個區域。指定函式overlay0放在自訂section .overlay0裡,要使用 attribute ((section(“.overlay0”)))語法, 完整寫法請參考圖表4a。圖表4b.是另外一種寫法。 
指定全域變數gdata1放在自訂section .overlay4裡,要使用 attribute ((section(“.overlay4”)))語法,完整寫法請參考圖表5。 ![]()
1.5 各 sections 的 LMA 與 VMA
圖表6,是各個section的LMA和VMA。在這個表上,可以看.andes32_init
到.sdata_w的LMA從0x0~0x29dc,這些section的LMA是連續的。.overlay0 與.overlay1做overlay,所以有共同的VMA 0x10800000。同樣的,.overlay2 .overlay3,具有共同的VMA 0x10804000。.Overlay4和.overlay5,也有同樣的VMA 0x18008000。 
1.6 overlay 程式的載入
前面已經介紹overlay section的sag檔寫法。那麼如何載入使用者想要用的overlay程式呢?
請看圖表7,這是overlay的執行程式碼。第5行OverlayLoad(0)表示載入section .overlay0。第6行OverlayLoad(4)表示載入section .overlay4。第7行在.overlay0被載入後,執行overlay0(),可以正常工作。
再來我們介紹一下Overlay manager的程式運作,Overlay manager即為圖表7中的函式OverlayLoad。圖表8列出Overlay manager程式碼片段,主要做了兩件事。一,修改mapped table _ovly_table,標示overlay section是mapped 或是unmapped。_ovly_table的用途是讓gdb知道目前載入的是哪一個section, 使得gdb在debug時,能自動切換為正確的除錯資訊。
二,在程式執行時期將函式載入,函式ovly_copy是一個memcpy函式,將函式從LMA複製到VMA上。當OverlayLoad(0)執行完後,overlay0函式主體便存在於VMA上,可正確的執行。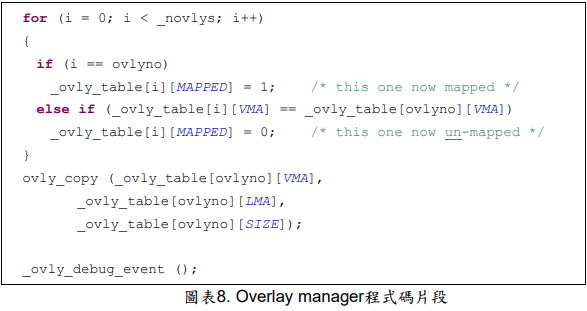
圖表9為_ovly_table的內容,要標示每一個overlay section的vma, size, lma, 和是否mapped。必須要注意的一點,_ovly_table要位在一個lma等於vma的區域裡。
2. 除錯 Overlay 的程式
開啟自動overlay除錯功能的gdb命令是overlay auto。當overlay auto開啟後, 對於使用者來說,與一般程式的除錯方法相同。
圖表8的最後一行_ovly_debug_event()的用途是讓gdb能把中斷點加在正確的地址上,這一行要寫在OverlayLoad的後面。必須要有這一行,gdb的自動overlay除錯才能正常。
當使用者加一個中斷點在被overlay的區域,gdb會在函式被載入之後(即為執行完OverlayLoad),遇到_ovly_debug_event時,自動的把中斷點加到overlay 的地址上。
3. 參考資料
Overlay Commands
https://sourceware.org/gdb/onlinedocs/gdb/Overlay-Commands.html
Automatic Overlay Debugging https://sourceware.org/gdb/onlinedocs/gdb/Automatic-Overlay-Debugging.html#Auto matic-Overlay-Debugging
Debugging Programs That Use Overlays http://davis.lbl.gov/Manuals/GDB/gdb_11.html
Andes BSP v3.2.0 User Manual
Chapter 12 “Linker Script Generation”
4. 結語
善用 overlay 技術可以更有效率的使用快速但昂貴的 SRAM,在執行時,容納比 SRAM 實際大小更大的程式,設計出高效率小面積的 IC。
